第八章 文本挖掘¶

What can be learned from 5 million books
https://www.bilibili.com/video/BV1jJ411u7Nd
This talk by Jean-Baptiste Michel and Erez Lieberman Aiden is phenomenal.
Michel, J.-B., et al. (2011). Quantitative Analysis of Culture Using Millions of Digitized Books. Science, 331, 176–182.
%%html
<iframe src="//player.bilibili.com/player.html?aid=68934891&bvid=BV1jJ411u7Nd&cid=119471774&page=1"
width=1000 height=600
scrolling="no" border="0" frameborder="no" framespacing="0" allowfullscreen="true"> </iframe>
试一下谷歌图书的数据: https://books.google.com/ngrams/
数据下载: http://www.culturomics.org/home
Bag-of-words model (BOW)¶
Represent text as numerical feature vectors
We create a vocabulary of unique tokens—for example, words—from the entire set of documents.
We construct a feature vector from each document that contains the counts of how often each word occurs in the particular document.
Since the unique words in each document represent only a small subset of all the words in the bag-of-words vocabulary, the feature vectors will consist of mostly zeros, which is why we call them sparse
“词袋模型”(Bag of words model)假定对于一个文本:
忽略词序、语法、句法;
将其仅仅看做是一个词集合或组合;
每个词的出现都是独立的,不依赖于其他词是否出现。
文本任意一个位置出现某一个词汇是独立选择的,不受前面句子的影响。
这种假设虽然对自然语言进行了简化,便于模型化。
Document-Term Matrix (DTM)
问题:例如在新闻个性化推荐中,用户对“南京醉酒驾车事故”这个短语很感兴趣。词袋模型忽略了顺序和句法,认为用户对“南京”、“醉酒”、“驾车”和“事故”感兴趣,因此可能推荐出和“南京”、“公交车”、“事故”相关的新闻。
解决方法: 可抽取出整个短语;或者采用高阶(2阶以上)统计语言模型。例如bigram、trigram来将词序保留下来,相当于bag of bigram和bag of trigram。
Transforming words into feature vectors¶
A document-term matrix or term-document matrix is a mathematical matrix that describes the frequency of terms that occur in a collection of documents.
In a document-term matrix, rows correspond to documents in the collection and columns correspond to terms.
There are various schemes for determining the value that each entry in the matrix should take. One such scheme is tf-idf. They are useful in the field of natural language processing.
D1 = “I like databases”
D2 = “I hate databases”
I |
like |
hate |
databases |
|
|---|---|---|---|---|
D1 |
1 |
1 |
0 |
1 |
D2 |
1 |
0 |
1 |
1 |
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(ngram_range=(1, 2))
docs = np.array([
'The sun is shining',
'The weather is sweet',
'The sun is shining and the weather is sweet'])
bag = count.fit_transform(docs)
count?
count.get_feature_names()
['and',
'and the',
'is',
'is shining',
'is sweet',
'shining',
'shining and',
'sun',
'sun is',
'sweet',
'the',
'the sun',
'the weather',
'weather',
'weather is']
print(count.vocabulary_) # word: position index
{'the': 10, 'sun': 7, 'is': 2, 'shining': 5, 'the sun': 11, 'sun is': 8, 'is shining': 3, 'weather': 13, 'sweet': 9, 'the weather': 12, 'weather is': 14, 'is sweet': 4, 'and': 0, 'shining and': 6, 'and the': 1}
type(bag)
scipy.sparse.csr.csr_matrix
print(bag.toarray())
[[0 0 1 1 0 1 0 1 1 0 1 1 0 0 0]
[0 0 1 0 1 0 0 0 0 1 1 0 1 1 1]
[1 1 2 1 1 1 1 1 1 1 2 1 1 1 1]]
import pandas as pd
pd.DataFrame(bag.toarray(), columns = count.get_feature_names())
| and | and the | is | is shining | is sweet | shining | shining and | sun | sun is | sweet | the | the sun | the weather | weather | weather is | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
| 2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 |
The sequence of items in the bag-of-words model that we just created is also called the 1-gram or unigram model: each item or token in the vocabulary represents a single word.
n-gram model¶
The choice of the number n in the n-gram model depends on the particular application
1-gram: “the”, “sun”, “is”, “shining”
2-gram: “the sun”, “sun is”, “is shining”
The CountVectorizer class in scikit-learn allows us to use different
n-gram models via its ngram_range parameter.
While a 1-gram representation is used by default
we could switch to a 2-gram representation by initializing a new CountVectorizer instance with ngram_range=(2,2).
TF-IDF¶
Assessing word relevancy via term frequency-inverse document frequency
\(tf(t, d)\) is the term frequency of term t in document d.
inverse document frequency \(idf(t)\) can be calculated as: \(idf(t) = log \frac{n_d}{1 + df(d, t)}\)
Question: Why do we add the constant 1 to the denominator ?
The tf-idf equation that was implemented in scikit-learn is as follows: \(tf*idf(t, d) = tf(t, d) \times (idf(t, d) + 1)\)
SKlearn use smooth_idf=True \(idf(t) = log \frac{1+n_d}{1 + df(d, t)} + 1\)
where \(n_d\) is the total number of documents, and \(df(d, t)\) is the number of documents \(d\) that contain the term \(t\).

TfidfTransformer¶
Scikit-learn implements yet another transformer, the TfidfTransformer, that takes the raw term frequencies from CountVectorizer as input and transforms them into tf-idfs:
from sklearn.feature_extraction.text import TfidfTransformer
np.set_printoptions(precision=2)
tfidf = TfidfTransformer(use_idf=True, norm='l2', smooth_idf=True)
print(tfidf.fit_transform(count.fit_transform(docs)).toarray())
[[0. 0. 0.31 0.4 0. 0.4 0. 0.4 0.4 0. 0.31 0.4 0. 0.
0. ]
[0. 0. 0.31 0. 0.4 0. 0. 0. 0. 0.4 0.31 0. 0.4 0.4
0.4 ]
[0.29 0.29 0.35 0.22 0.22 0.22 0.29 0.22 0.22 0.22 0.35 0.22 0.22 0.22
0.22]]
from sklearn.feature_extraction.text import TfidfTransformer
np.set_printoptions(precision=2)
tfidf = TfidfTransformer(use_idf=True, norm=None, smooth_idf=True)
print(tfidf.fit_transform(count.fit_transform(docs)).toarray())
[[0. 0. 1. 1.29 0. 1.29 0. 1.29 1.29 0. 1. 1.29 0. 0.
0. ]
[0. 0. 1. 0. 1.29 0. 0. 0. 0. 1.29 1. 0. 1.29 1.29
1.29]
[1.69 1.69 2. 1.29 1.29 1.29 1.69 1.29 1.29 1.29 2. 1.29 1.29 1.29
1.29]]
import pandas as pd
bag = tfidf.fit_transform(count.fit_transform(docs))
pd.DataFrame(bag.toarray(), columns = count.get_feature_names())
| and | and the | is | is shining | is sweet | shining | shining and | sun | sun is | sweet | the | the sun | the weather | weather | weather is | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.000000 | 1.0 | 1.287682 | 0.000000 | 1.287682 | 0.000000 | 1.287682 | 1.287682 | 0.000000 | 1.0 | 1.287682 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 1.0 | 0.000000 | 1.287682 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.287682 | 1.0 | 0.000000 | 1.287682 | 1.287682 | 1.287682 |
| 2 | 1.693147 | 1.693147 | 2.0 | 1.287682 | 1.287682 | 1.287682 | 1.693147 | 1.287682 | 1.287682 | 1.287682 | 2.0 | 1.287682 | 1.287682 | 1.287682 | 1.287682 |
# 一个词的tfidf值
import numpy as np
tf_is = 2.0
n_docs = 3.0
# smooth_idf=True & norm = None
idf_is = np.log((1+n_docs) / (1+3)) + 1
tfidf_is = tf_is * idf_is
print('tf-idf of term "is" = %.2f' % tfidf_is)
tf-idf of term "is" = 2.00
# *最后一个文本*里的词的tfidf原始数值(未标准化)
tfidf = TfidfTransformer(use_idf=True, norm=None, smooth_idf=True)
raw_tfidf = tfidf.fit_transform(count.fit_transform(docs)).toarray()[-1]
raw_tfidf, count.get_feature_names()
(array([1.69, 1.69, 2. , 1.29, 1.29, 1.29, 1.69, 1.29, 1.29, 1.29, 2. ,
1.29, 1.29, 1.29, 1.29]),
['and',
'and the',
'is',
'is shining',
'is sweet',
'shining',
'shining and',
'sun',
'sun is',
'sweet',
'the',
'the sun',
'the weather',
'weather',
'weather is'])
# l2标准化后的tfidf数值
l2_tfidf = raw_tfidf / np.sqrt(np.sum(raw_tfidf**2))
l2_tfidf
array([0.29, 0.29, 0.35, 0.22, 0.22, 0.22, 0.29, 0.22, 0.22, 0.22, 0.35,
0.22, 0.22, 0.22, 0.22])
政府工作报告文本挖掘¶
0. 读取数据¶
with open('./data/gov_reports1954-2021.txt', 'r', encoding = 'utf-8') as f:
reports = f.readlines()
len(reports)
52
print(reports[-7][:1000])
1964 1964年国务院政府工作报告(摘要)——1964年12月21日和22日在第三届全国人民代表大会第一次会议上 国务院总理周恩来 五年来,我国各族人民在中国共产党的英明领导下,高举毛泽东思想的光辉旗帜,坚持鼓足干劲、力争上游、多快好省地建设社会主义的总路线,在全国范围内开展了阶级斗争、生产斗争、科学实验三大革命运动,有力地反击了资本主义和封建势力的进攻,提高了人民群众的社会主义觉悟,基本上完成了调整国民经济的任务,使工农业生产全面高涨,整个国民经济全面好转,我国自力更生的力量大为增强。同时,在国际上,我们同美帝国主义、各国反动派和现代修正主义进行了针锋相对的斗争,打退了他们掀起的一次又一次的反华高潮;积极地支援了各国革命人民,发展了同许多国家的友好合作关系;我国的国际威望更加提高了,我们的朋友遍天下。 我们要进一步开展社会主义教育运动,坚决依靠工人阶级、贫农下中农、革命的干部、革命的知识分子和其他革命分子,根据社会主义的彻底革命的原则,在政治、经济、思想和组织这四个方面,进行清理和基本建设,在人民群众中深刻地进行一次阶级教育和社会主义教育;要进一步开展思想文化战线上的社会主义革命,逐步实现知识分子劳动化,劳动人民知识化;要进一步巩固和发展人民民主统一战线,加强各民族的大团结;各级机关和各级干部必须革命化,都要学习解放军、大庆、大寨的彻底革命的精神和工作作风。在深入广泛开展社会主义教育运动的基础上,一九六五年要大力组织工农业生产的新高潮,为一九六六年开始的第三个五年计划作好准备,争取在不太长的历史时期内,把我国建成一个具有现代农业、现代工业、现代国防和现代科学技术的社会主义强国。在国际方面,我们要继续贯彻我国对外政策的总路线,同全世界人民一起,坚决反对美帝国主义及其走狗,为争取世界和平、民族解放、人民民主和社会主义事业的新胜利而奋斗。 国民经济的成就和今后的建设任务 周恩来总理在报告中首先指出,从第二届全国人民代表大会第一次会议以来,我国各族人民,在中国共产党的英明领导下,高举毛泽东思想的光辉旗帜,坚持鼓足干劲、力争上游、多快好省地建设社会主义的总路线,在全国范围内展开了阶级斗争、生产斗争、科学实验三大革命运动,在国际上同帝国主义、各国反动派和现代修正主义进行了针锋相对的斗争,取得了一个又一个的伟大胜
print(reports[4][:500])
1959 1959年国务院政府工作报告 ——1959年4月18日在第二届全国人民代表大会第一次会议上 国务院总理周恩来 各位代表: 我现在根据国务院的决定,向第二届全国人民代表大会第一次会议作政府工作报告。 一、第一个五年计划时期内和第二个五年计划的第一年——一九五八年的伟大成就 在第一届全国人民代表大会的四年多的任期中间,我们的国家经历了一系列的具有重大历史意义的变化。 当一九五四年第一届全国人民代表大会第一次会议召开的时候,我国社会主义经济已经在国民经济中居于主导的地位,但是,我国还存在着大量的资本主义的工业和商业,并且大量地存在着个体的农业和手工业。农村中劳动互助运动已经广泛地发展起来,参加农业劳动互助组的农户达到了百分之六十左右,但是,组成农业生产合作社的农户还只占农户总数的百分之二左右。在那时候,我国已经完成了经济恢复时期的任务,开始了大规模的、有计划的经济建设。但是,究竟我们能不能在一个较短的时间内,使我国这样一个有六亿多人口的大国,建立起社会主义工业化的基础来,还有待于事实的证明。而现在呢?大家看到,只经过四年
pip install jieba
https://github.com/fxsjy/jieba
pip install wordcloud
https://github.com/amueller/word_cloud
pip install gensim
pip install gensim
Collecting gensim
Downloading gensim-3.8.3-cp37-cp37m-macosx_10_9_x86_64.whl (24.2 MB)
|████████████████████████████████| 24.2 MB 376 kB/s eta 0:00:01
?25hRequirement already satisfied: scipy>=0.18.1 in /opt/anaconda3/lib/python3.7/site-packages (from gensim) (1.4.1)
Requirement already satisfied: numpy>=1.11.3 in /opt/anaconda3/lib/python3.7/site-packages (from gensim) (1.18.1)
Requirement already satisfied: six>=1.5.0 in /opt/anaconda3/lib/python3.7/site-packages (from gensim) (1.14.0)
Collecting smart-open>=1.8.1
Downloading smart_open-2.0.0.tar.gz (103 kB)
|████████████████████████████████| 103 kB 625 kB/s eta 0:00:01
?25hRequirement already satisfied: requests in /opt/anaconda3/lib/python3.7/site-packages (from smart-open>=1.8.1->gensim) (2.22.0)
Requirement already satisfied: boto in /opt/anaconda3/lib/python3.7/site-packages (from smart-open>=1.8.1->gensim) (2.49.0)
Requirement already satisfied: boto3 in /opt/anaconda3/lib/python3.7/site-packages (from smart-open>=1.8.1->gensim) (1.9.191)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/anaconda3/lib/python3.7/site-packages (from requests->smart-open>=1.8.1->gensim) (1.25.8)
Requirement already satisfied: certifi>=2017.4.17 in /opt/anaconda3/lib/python3.7/site-packages (from requests->smart-open>=1.8.1->gensim) (2019.11.28)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /opt/anaconda3/lib/python3.7/site-packages (from requests->smart-open>=1.8.1->gensim) (3.0.4)
Requirement already satisfied: idna<2.9,>=2.5 in /opt/anaconda3/lib/python3.7/site-packages (from requests->smart-open>=1.8.1->gensim) (2.8)
Requirement already satisfied: s3transfer<0.3.0,>=0.2.0 in /opt/anaconda3/lib/python3.7/site-packages (from boto3->smart-open>=1.8.1->gensim) (0.2.1)
Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in /opt/anaconda3/lib/python3.7/site-packages (from boto3->smart-open>=1.8.1->gensim) (0.9.5)
Requirement already satisfied: botocore<1.13.0,>=1.12.191 in /opt/anaconda3/lib/python3.7/site-packages (from boto3->smart-open>=1.8.1->gensim) (1.12.191)
Requirement already satisfied: docutils>=0.10 in /opt/anaconda3/lib/python3.7/site-packages (from botocore<1.13.0,>=1.12.191->boto3->smart-open>=1.8.1->gensim) (0.16)
Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /opt/anaconda3/lib/python3.7/site-packages (from botocore<1.13.0,>=1.12.191->boto3->smart-open>=1.8.1->gensim) (2.8.1)
Building wheels for collected packages: smart-open
Building wheel for smart-open (setup.py) ... ?25ldone
?25h Created wheel for smart-open: filename=smart_open-2.0.0-py3-none-any.whl size=101341 sha256=373e4939f516de66ae607886c52d7a00529e0930868ce9f5ae1ecec2297f40f4
Stored in directory: /Users/datalab/Library/Caches/pip/wheels/bb/1c/9c/412ec03f6d5ac7d41f4b965bde3fc0d1bd201da5ba3e2636de
Successfully built smart-open
Installing collected packages: smart-open, gensim
Successfully installed gensim-3.8.3 smart-open-2.0.0
Note: you may need to restart the kernel to use updated packages.
%matplotlib inline
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import sys
import numpy as np
from collections import defaultdict
import statsmodels.api as sm
from wordcloud import WordCloud
import jieba
import matplotlib
import gensim
from gensim import corpora, models, similarities
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
#matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #指定默认字体
matplotlib.rc("savefig", dpi=400)
# 为了确保中文可以在matplotlib里正确显示
#matplotlib.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #指定默认字体
# 需要确定系统安装了Microsoft YaHei
# import matplotlib
# my_font = matplotlib.font_manager.FontProperties(
# fname='/Users/chengjun/github/cjc/data/msyh.ttf')
1. 分词¶
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
Full Mode: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
Default Mode: 我/ 来到/ 北京/ 清华大学
他, 来到, 了, 网易, 杭研, 大厦
小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
2. 停用词¶
filename = './data/stopwords.txt'
stopwords = {}
f = open(filename, 'r')
line = f.readline().rstrip()
while line:
stopwords.setdefault(line, 0)
stopwords[line] = 1
line = f.readline().rstrip()
f.close()
adding_stopwords = [u'我们', u'要', u'地', u'有', u'这', u'人',
u'发展',u'建设',u'加强',u'继续',u'对',u'等',
u'推进',u'工作',u'增加']
for s in adding_stopwords: stopwords[s]=10
3. 关键词抽取¶
基于TF-IDF 算法的关键词抽取¶
import jieba.analyse
txt = reports[-1]
tf = jieba.analyse.extract_tags(txt, topK=200, withWeight=True)
u"、".join([i[0] for i in tf[:50]])
'人民、我们、国家、我国、一九五三年、工业、一九五四年、必须、工作、建设、发展、和平、一九四九年、社会主义、一九五、国家机关、生产、计划、全国、农业、亚洲、美国、事业、企业、应当、经济、这些、改造、增加、并且、完成、但是、已经、等于、合作社、集团、方面、需要、台湾、资本主义、反对、几年、生活、建立、为了、技术、这个、进行、日内瓦、问题'
plt.hist([i[1] for i in tf])
plt.show()
基于 TextRank 算法的关键词抽取¶
tr = jieba.analyse.textrank(txt,topK=200, withWeight=True)
u"、".join([i[0] for i in tr[:50]])
'国家、人民、工业、发展、建设、工作、生产、美国、企业、经济、计划、社会主义、中国、进行、全国、技术、亚洲、集团、需要、问题、农业、方面、完成、建立、台湾、生活、事业、没有、改造、应当、资本主义、增加、关系、组织、保证、会议、侵略、不能、注意、加强、战争、提高、社会、文化、继续、政府、现代化、能够、日内瓦、世界'
plt.hist([i[1] for i in tr])
plt.show()
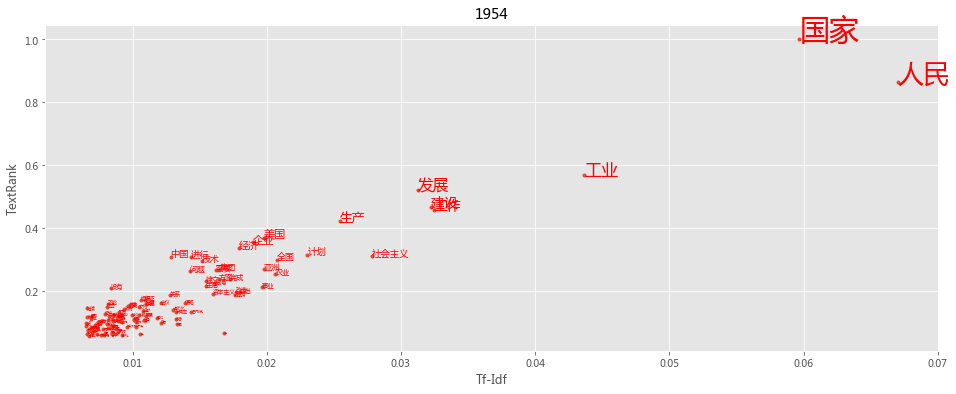
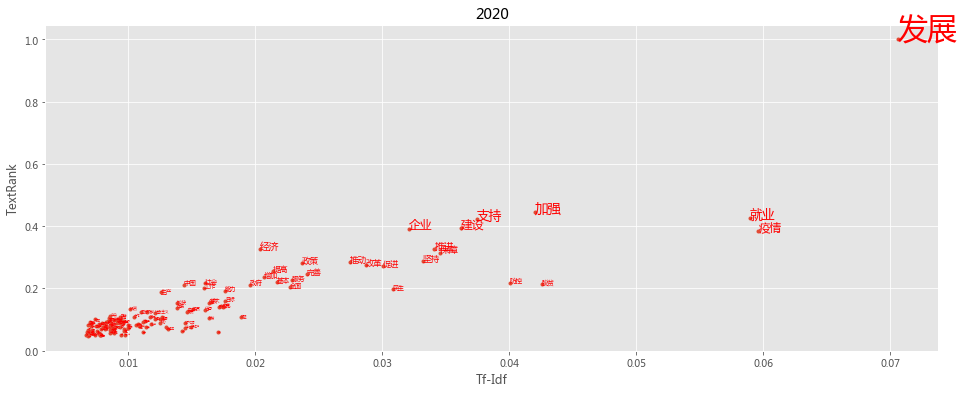
import pandas as pd
def keywords(index):
txt = reports[-index]
tf = jieba.analyse.extract_tags(txt, topK=200, withWeight=True)
tr = jieba.analyse.textrank(txt,topK=200, withWeight=True)
tfdata = pd.DataFrame(tf, columns=['word', 'tfidf'])
trdata = pd.DataFrame(tr, columns=['word', 'textrank'])
worddata = pd.merge(tfdata, trdata, on='word')
fig = plt.figure(figsize=(16, 6),facecolor='white')
plt.plot(worddata.tfidf, worddata.textrank, linestyle='',marker='.')
for i in range(len(worddata.word)):
plt.text(worddata.tfidf[i], worddata.textrank[i], worddata.word[i],
fontsize = worddata.textrank[i]*30,
color = 'red', rotation = 0
)
plt.title(txt[:4])
plt.xlabel('Tf-Idf')
plt.ylabel('TextRank')
plt.show()
plt.style.use('ggplot')
keywords(1)
keywords(-1)
TextRank: Bringing Order into Texts
基本思想:
将待抽取关键词的文本进行分词
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
计算图中节点的PageRank,注意是无向带权图
4. 词云¶
def wordcloudplot(txt, year):
wordcloud = WordCloud(font_path='../data/msyh.ttf').generate(txt)
# Open a plot of the generated image.
fig = plt.figure(figsize=(16, 6),facecolor='white')
plt.imshow(wordcloud)
plt.title(year)
plt.axis("off")
#plt.show()
基于tfidf过滤的词云¶
txt = reports[-1]
tfidf200= jieba.analyse.extract_tags(txt, topK=200, withWeight=False)
seg_list = jieba.cut(txt, cut_all=False)
seg_list = [i for i in seg_list if i in tfidf200]
txt200 = r' '.join(seg_list)
wordcloudplot(txt200, txt[:4])

txt = reports[-2]
tfidf200= jieba.analyse.extract_tags(txt, topK=200, withWeight=False)
seg_list = jieba.cut(txt, cut_all=False)
seg_list = [i for i in seg_list if i in tfidf200]
txt200 = r' '.join(seg_list)
wordcloudplot(txt200, txt[:4])

wordfreq = defaultdict(int)
for i in seg_list:
wordfreq[i] +=1
wordfreq = [[i, wordfreq[i]] for i in wordfreq]
wordfreq.sort(key= lambda x:x[1], reverse = True )
u"、 ".join([ i[0] + u'(' + str(i[1]) +u')' for i in wordfreq ])
'发展(125)、 改革(68)、 推进(65)、 建设(54)、 经济(52)、 加强(45)、 推动(42)、 加快(40)、 政府(36)、 创新(36)、 完善(35)、 企业(35)、 全面(35)、 促进(34)、 提高(32)、 就业(31)、 实施(31)、 中国(31)、 支持(29)、 深化(29)、 政策(28)、 服务(27)、 国家(26)、 人民(26)、 工作(26)、 制度(25)、 我们(25)、 深入(25)、 社会(25)、 增长(25)、 群众(24)、 坚持(24)、 今年(23)、 继续(23)、 地区(22)、 扩大(22)、 农村(20)、 坚决(20)、 机制(19)、 治理(19)、 稳定(19)、 地方(19)、 保障(18)、 安全(18)、 保护(18)、 持续(17)、 合作(17)、 市场(17)、 重点(17)、 实现(17)、 消费(16)、 投资(16)、 综合(16)、 落实(16)、 试点(16)、 结构(15)、 有效(15)、 维护(15)、 加大(15)、 产能(15)、 积极(15)、 领域(15)、 教育(15)、 改善(14)、 国际(14)、 国内(14)、 城市(14)、 我国(14)、 生态(14)、 以上(14)、 基本(14)、 问题(14)、 强化(13)、 增加(13)、 农业(13)、 提升(13)、 制定(13)、 力度(13)、 质量(13)、 引导(13)、 降低(13)、 依法(12)、 战略(12)、 升级(12)、 重要(12)、 标准(12)、 作用(12)、 健康(12)、 保持(12)、 增强(12)、 生产(12)、 文化(12)、 更加(12)、 必须(12)、 创业(12)、 目标(12)、 民生(12)、 下降(12)、 确保(11)、 取得(11)、 供给(11)、 生活(11)、 核心(11)、 规范(11)、 环境(11)、 收费(11)、 进一步(11)、 管理(11)、 做好(10)、 完成(10)、 资金(10)、 能力(10)、 不断(10)、 开展(10)、 产业(10)、 健全(10)、 水平(10)、 科技(10)、 体系(10)、 风险(10)、 世界(10)、 鼓励(10)、 重大(10)、 一年(10)、 监管(10)、 一批(10)、 困难(10)、 突出(9)、 代表(9)、 责任(9)、 金融(9)、 全国(9)、 大力(9)、 行政(9)、 区域(9)、 体制改革(9)、 减少(9)、 贯彻(9)、 组织(9)、 经济社会(9)、 国务院(8)、 各位(8)、 协调(8)、 制造(8)、 发挥(8)、 合理(8)、 优化(8)、 扶贫(8)、 调控(8)、 习近平(8)、 党中央(8)、 专项(8)、 动能(8)、 现代化(8)、 资源(8)、 城镇(8)、 行动(8)、 文明(7)、 全年(7)、 取消(7)、 住房(7)、 新型(7)、 万人(7)、 特色(7)、 生产总值(7)、 出台(7)、 引领(7)、 城乡(7)、 实体(7)、 更好(7)、 基础设施(7)、 和谐(7)、 高校(7)、 脱贫(7)、 改造(7)、 抓好(6)、 严肃查处(6)、 转型(6)、 新兴产业(6)、 打造(6)、 互联网(6)、 对外开放(6)、 补助(6)、 结构性(6)、 扎实(6)、 减税(6)、 涉企(6)、 培育(6)、 补短(6)、 办好(5)、 双创(5)、 精准(5)、 督查(5)、 试验区(5)、 医保(5)、 政策措施(5)、 实干(5)、 2000(4)、 降费(4)、 问责(4)'
基于停用词过滤的词云¶
#jieba.add_word('股灾', freq=100, tag=None)
txt = reports[-1]
seg_list = jieba.cut(txt, cut_all=False)
seg_list = [i for i in seg_list if i not in stopwords]
txt = r' '.join(seg_list)
wordcloudplot(txt, txt[:4])
#file_path = '/Users/chengjun/GitHub/cjc2016/figures/wordcloud-' + txt[:4] + '.png'
#plt.savefig(file_path,dpi = 300, bbox_inches="tight",transparent = True)

绘制1954-2016政府工作报告词云¶
#jieba.add_word('股灾', freq=100, tag=None)
for txt in reports:
seg_list = jieba.cut(txt, cut_all=False)
seg_list = [i for i in seg_list if i not in stopwords]
txt = r' '.join(seg_list)
wordcloudplot(txt, txt[:4])
file_path = '../figure/wordcloud-' + txt[:4] + '.png'
plt.savefig(file_path,dpi = 400, bbox_inches="tight",\
transparent = True)

5. 词向量的时间序列¶
reports[0][:500]
'1954\t1954年政府工作报告——1954年5月23日在中华人民共和国第一届全国人民代表大会第一次会议上\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\xa0 国务院总理周恩来各位代表:\u3000\u3000我们第一届全国人民代表大会第一次会议,在听了刘少奇同志关于宪法草案的报告并进行了三天的讨论以后,已经光荣地完成了一件历史性的工作,通过了我们国家的根本法——中华人民共和国宪法,接着,又通过了几个重要的法律。现在,我代表中央人民政府作工作报告。\u3000\u3000我国伟大的人民革命的根本目的,是在于从帝国主义、封建主义和官僚资本主义的压迫下面,最后也从资本主义的束缚和小生产的限制下面,解放我国的生产力,使我国国民经济能够沿着社会主义的道路而得到有计划的迅速的发展,以便提高人民的物质生活和文化生活的水平,并且巩固我们国家的独立和安全。我国的经济原来是很落后的;如果我们不建设起强大的现代化的工业、现代化的农业、现代化的交通运输业和现代化的国防,我们就不能摆脱落后和贫困,我们的革命就不能达到目的。在一九四九年至一九五二年间,中央人民政府按照中国人民政治协商会议共同纲领的规定,先后完成了全国大陆的统一,完成了土地制度的改革,进'
reports[1][:500]
'1955\t1955年国务院政府工作报告关于发展国民经济的第一个五年计划的报告\xa0——1955年7月5日至6日在第一届全国人民代表大会第二次会议上\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\xa0 国务院副总理兼国家计划委员会主任李富春目录\xa0 一、国家在过渡时期的总任务\xa0 二、第一个五年计划概要\xa0 三、第一个五年计划的若干问题\xa0 (一)关于工业和运输业的基本建设问题\xa0 (二)关于工业的生产问题\xa0 (三)关于农业的增产问题\xa0 (四)关于对资本主义工商业的社会主义改造问题\xa0 (五)关于保证市场的稳定问题\xa0 (六)关于培养建设干部问题\xa0 (七)关于提高人民的物质生活和文化生活的水平问题\xa0 (八)关于厉行节约问题\xa0 (九)关于苏联和各人民民主国家同我国建设的关系\u3000四、为完成和超额完成第一个五年计划而奋斗\t\t\u3000\u3000各位代表:\u3000\u3000中华人民共和国国务院向第一届全国人民代表大会第二次会议提出关于发展国民经济第一个五年计划的议案,我现在代表国务院向本次大会作关于第一个五年计划的报告。\u3000\u3000中华人民共和国发展国民经济的第一个五年计划草案,是在中国共产党中央委员会和毛泽东主席的直接领导下编制完成的。一九五五年三月间经过中国共产党的全国代表会'
test = jieba.analyse.textrank(reports[0], topK=200, withWeight=False)
test = jieba.analyse.extract_tags(reports[1], topK=200, withWeight=False)
import jieba.analyse
wordset = []
for k, txt in enumerate(reports):
print(k)
top200= jieba.analyse.extract_tags(txt, topK=200, withWeight=False)
for w in top200:
if w not in wordset:
wordset.append(w)
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
len(wordset)
2718
print(' '.join(wordset))
发展 建设 推进 加强 完善 创新 实施 就业 促进 推动 体系 坚持 改革 支持 市场主体 脱贫 加快 企业 健全 全面 服务 经济 机制 提升 社会 深化 保障 稳定 优化 防控 提高 政策 疫情 战略 高质量 持续 民生 保持 强化 基本 国家 习近平 科技 农村 工作 扩大 构建 力度 社会主义 目标 加大 继续 区域 帮扶 落实 现代化 安全 能力 制度 重大 监管 统筹 成果 保护 行动 人民 乡村 深入 做好 政府 中国 基础 增长 工程 取得 教育 贯彻 任务 城镇 实现 扎实 降低 健康 领域 农业 消费 精神 巩固 治理 城乡 试点 合作 合理 国内 融合 更好 处置 党中央 水平 改善 国际 文化 生活 努力 坚决 抗疫 小微 及时 增加 十四五 有效 市场化 规范 拓展 生产 中小 万亿元 市场 维护 协同 高水平 弘扬 新型 产业 公共卫生 投资 我们 地区 经济社会 基层 整治 进一步 活力 开放 住房 核心 重点 金融 增强 振兴 质量 残疾人 生态 数字 工商户 生产总值 贷款 稳步 防范 攻坚 发挥 高标准 常态 经济运行 开展 群众 放管服 100 体制 制定 实体 引导 强军 积极 共建 环境 中央 挑战 减税 精准 有序 各位 特色 营商 职业技能 科学 各类 协定 我国 公共服务 基础设施 综合 产业链 今年 公平 关键 恢复 粮食 全国 更加 能源 繁荣 绿色 作用 攻坚战 宏观政策 完成 代表 监督 攻关 扶贫 人员 小康社会 降费 困难 自贸 失业 激发 坚定 大力 减免 创业 贫困人口 复工 支出 农民 重要 领导人 医疗 改革开放 去年 努力完成 防治 建成 电商 同志 出台 扶持 举措 培育 新冠 复产 六稳 六保 投入 安排 各国 研发 设施 一定 各族人民 共享 农民工 坚强 海外侨胞 制造业 鼓励 高校 万人 应急 养老 主要 低保 台湾同胞 广大 全年 大幅 专项 负责制 防疫 服务业 规划 全部 试验区 形式主义 打赢 成本 物资 诚挚 依法 延长 风险 问题 贫困地区 地方 收费 融资 污染 以上 解决 确保 三大 负担 财政 一批 医保 结构 办好 公平竞争 审批 改造 结构性 退役军人 压减 主体 互联网 缴费 民营 化解 公正 切实 抓好 压力 稳妥 下降 不断 各级 2019 提质 70 3% 8000 实际 关系 缓解 供给 事项 区间 五年 着力 世界 30% 变革 标准 协调 产能 管理 升级 民族 年均 重塑 业态 思想 多万 宏观调控 范围 决胜 转移 时代 增速 项目 政府职能 多渠道 2018 稳中 动能 成效 激励 债务 制造 支付 倾斜 涉企 补短 体制改革 城市 严肃查处 双创 调控 实干 必须 行政 责任 突出 引领 一年 国务院 督查 和谐 补助 对外开放 问责 2000 减少 文明 新兴产业 取消 资金 组织 打造 资源 转型 政策措施 城镇化 法治 国有企业 新增 2020 方式 大国 贸易 启动 建立 覆盖 实行 万公里 棚户区 基金 达到 网络 现代 规模 中西部 强国 推广 80% 6.5% 人口 三是 救助 万套 自贸区 公共 深化改革 下放 城乡居民 环保 收入 海洋 国防 定向 矛盾 示范区 核准 铁路 养老保险 价格 修订 谈判 事业 清单 机关 经济带 危房改造 管理制度 左右 交通 2014 预算 结构调整 探索 7.5% 比重 资本 事业单位 节能 食品药品 公开 简政放权 淘汰 人均 机构 投融资 总体 2007 2012 转变 货币政策 保障性 和平 社会保障 形成 累计 义务教育 金融危机 财政政策 显著 居民消费 服务体系 物价 城镇居民 长远 纲要 安居工程 财政赤字 冲击 三农 两岸关系 技术 学生 经费支出 明显增强 人才 调整 坚实基础 自治 应对 财税 大力发展 4% 小型 平稳 微型 农产品 学前教育 分配 理顺 参保 减排 增值税 大病 中小学 营业税 人民币 控制 流通 2011 10 三网 特别 需求 新农 改征 适度 中央财政 总量 十二五 坚定不移 共同 扶贫开发 句細 跺害 浠锋 鍥介 绯伙 氫繚 崗璋 缓绔嬪 鍛樺 鍥界 氫富 跺涵 鍥藉 備腑 缓璁 鍥伴 缓璁剧 爺绌 鑲层 瑰紡 板缓 細淇 鑲叉 涓嶇 轰富 噸鐐 備繚 绯汇 姹傘 洪噸 翠腑 備弗 缓鏈 嬪缓 2010 鑲查 暱鏈 夸腑 戒汉 浠嶇 归潰 潰鍔 備互 十一五 4500 40% 4.45 23 戒富 储鍔 跨編 稿崗璋 鍥寸 10% 鑲诧 茶川 1500 1000 繚鍋 汉鎵 奖瑙 壓鏈 绮剧 氫腑 娴峰 病鏈 鍥為 变簡 轰腑 鏈虹 宠緝 冲績 堕暱 7% 備績 簰鍔 颁汉 16% 8% 抽噸 虹瓚 鑼冪 俊璐锋 环姣 50 渤娴 介噸 缓璁句 夸环 舵斂 浠峰 轰俊 堕噸 重大进展 第十一届 演变成 全国人民代表大会 第四次 中华民族 百年 报告 温家宝 国民经济 自主 有力 奋勇前进 总理 超级计算机 翠环 迈上 39.8 11.2% 3.16 8.31 探月 5771 9.7% 8.9% 2.97 1.18 43.7% 15.3% 23.6% 灾后 14.8% 外需 23% 1335 1226 25% 54641 5919 7356 鍥猴 2.15 暱璐 板伐 2.5 村缓 1.6 63.9 3.3 33 1.7 數瑁 寸數 9601 384 數鏈 7210 2529 遍潰 存薄 19.1% 12.45% 14.29% 轰績 规斂 鐐规 充汉 備富 撲汉 芥斂 鏈洪 借浆 烘斂 稿績 備负 饱琛 數缃 氫骇 氫俊 夸汉 己璋 鏈恒 绉嶇 兼定 俊璐峰 鍥虹 繚鏈 鍛姐 娴锋 轰负 鍥板 鍥姐 歌浆 苟璐 氫細 腐婢 備袱 轰袱 鍥斤 轰汉 快速增长 汽车 极大 灾区 亿元 坚实 重建 第三次 上年 刘卫兵 家电 蓬勃生机 隆重庆祝 下滑 抚今追昔 道路 请予 面之广 无私援助 大爱 張鏈 锋父 鍥哄伐 伴潰 夸繚 剁獎 轰唤 戒績 簡灏变 昏浆 村張 鑲叉斂 鍥拌 婀惧 鏈嬪 潰鍋 撲細 鏈嶇 肩淮 尝鍔 惧害 煙娼 樹簾 富鍔 冨眾 轰互 筹紱 磋储 嶄細 俊璐风 繚淇 硅法 按骞充 逛俊璐枫 曠數 创鑼 懇鎵 互鎵 悶鍔 哗宸 緱璧峰 跺洶 氫互 慨璁 互宸 潰婧 滄斂 曠伯 滅背 绉嶇伯 疆琛 创璧 绘瘡 害姣 四是 补贴 五是 两岸 二是 一是 出口 中小企业 民主 全面实施 抓紧 来自 措施 同胞 家庭 医药卫生 新型农村 对外 经营 方面 军队 2002 进展 借储 归噸 2008 剧兢 2006 備汉 韩鏈 戒袱 夸负 4.8% 鍥达 步伐 顺利 万公顷 国有 迈出 万吨 电信 4140 36 潰瓒 15 2005 翠汉 數瑙 鍋垮 妇鍔 簡璁 负鏈 強鏃 绘斂 噸鍋 虹伯 強骞 翠富 虫定 戒互 缓璁炬 備節 按婧 硅储 规不 氫汉 備弗鑲 版咕 成效显著 农业税 开发 县乡 用于 土地 第六位 非公有制 初步 逐步完善 明显 突破性 新进展 得到 拖欠 500 草案 存在 两基 万名 一些 偏快 2003 112 1.2% 撮噸 嬪伐 外贸顺差 抗灾救灾 分别 三年 感谢 合作医疗 体育事业 法规 投放 群众利益 连续 节能降耗 增幅 工程款 工作力度 约束性 社会治安 抚恤 高污染 继续加强 广泛开展 工资 第十届 高耗能 提出 大幅度提高 最低 行业 社会保险 历史 指标 部分 污染物 能耗 西部 增产 医疗卫生 艾滋病 紙鑽 绀句細 氫嚎 轰簡 个省 浣嶇疆 婁腑 噸瑙 过快 信访 国债资金 贫困家庭 生产能力 28 1700 30 紡杞 负鍔 200 俊璐 眾浜 浠樸 惰储 夸埂璐 紡涓 繃璋 哄績 鐐瑰伐 缓璁鹃 轰汉鎵 辩害 42 鍥藉師 滅畝 伴樁 卫生 下岗职工 种粮 各项 深入开展 关键环节 退税 专项资金 突发 教科书 全局 环境保护 发展观 2004 崇兢 经济体制 固定资产 油运 客观规律 注重 部门 煤电 注重实效 13 800 290 绀句 細璧 悶濂 樺害 剧畝 細璁 敖鏈 增收 积极性 预案 放开 遏制 清理 体制性 依法行政 各项事业 法律手段 商业银行 成就 切身利益 非典 辨斂 數鍔 悶濂介 画鍋 淇濃 插缓 高度重视 抗击 股份制 亿美元 清醒 整顿 武警部队 困难群众 开拓创新 十六大 法制建设 预防 部署 三个代表 内地 反腐败 干部 市场秩序 资金投入 城市居民 研究 监督管理 作出 事件 多年 救治 传染病 财力 统一 采取措施 毕业生 采取 办法 合法权益 领导 国有资产 逐步 精神文明 不断加强 公里 归暱 鍛樸 取得成效 不断扩大 总和 体育 市场经济 水利建设 平方米 明显提高 每年 大幅度 医疗保险 水利枢纽 平均 澳门 依法治国 公路 侨务工作 薄琛 颁績 氮璐 鍥戒 鑷冲 浠锋暈 峰績 负瑙 鐮翠骇 滅嚎 互璐 爺鏈 村伐 鐮村 樹簡 戒俊 數瀛 鍍氫富 曠兢 潰璐 普及 居民家庭 小康水平 本届 姜娲 江泽民 离退休 养老金 严重 互瑙 互琛 骇璐 婚噸 逛富 芥悶 簡寰 氫汉鎵 俊瑾 不鏈 細鍔 鑷村 显著成绩 民主法制 团结奋斗 秩序 七一 年末 十五届 复杂多变 六中全会 农民收入 重大项目 国际形势 党和国家 重要讲话 有利条件 快速 高新技术 保护主义 较大 计划 会议 电网 方针 效益 有些 前进 中国共产党 缓慢 农村用电 积累 具有 正确 科学内涵 公安干警 阔步前进 勤俭建国 违法活动 举办权 有法不依 统揽全局 斗争 加入 干堤 农村税费 立案查处 競璐 洶琛 冲洶 九五 2001 画娣 五年计划 短缺 同时 1995 樹汉 數锛 画鎵 悶濂界 持续增长 第十个 科研院所 迅速 时期 通货紧缩 办成 战略目标 高技术 香港 历史性 技术改造 大中型 注意 扩大内需 克服 祖国 通货膨胀 成绩 拉动 根据 过剩 国债 抑制 其他 奢侈浪费 始终 扭亏增盈 平衡 89404 8.3 1980 13380 16.5 2392 1997 2.9 4743 2492 69 67 2894 79.6 1656 920 2253 6280 4.7 5.7 10.6 863 诸多矛盾 想办 插伐 脱困 1999 工业 揣鍋 卞洶 不宸 崇淮 氮璐广 这些 认真贯彻 广大干部 回升 果断 改组 经济效益 政治 知难而进 各种 势头 增盈 南联盟 法轮功 主动精神 控股 政治素质 滞销产品 2202 52 967 77 27 1501 11377 1949 1547 47 之大是 日起 540 8400 滑闈 交灏变 互淇 繃璐 2100 4200 5100 6100 3358 1423 643 競闈 90 250 鍛樹細 21 金融风险 1998 艰储 斂璐 剧疆 鍥解 鐘舵 亚洲 五十周年 城乡人民 抗洪 贬值 扩大出口 洪涝灾害 工作进展 经济秩序 长江 大多数 预定 外汇储备 多项 成立 增长速度 战胜 难度 比较 正在 迎接 决策 逃汇 科教兴国 年初 奋发进取 财经纪律 乱摊派 姜琛 抗洪抢险 情况 影响 7.8 19 14 航段 团结奋战 骗汇 600 40 29 不旺 回归祖国 一手 科技进步 经验 条件 已经 逐年 变骇 勾宸 樹妇 鍥版 婀剧 集体主义 增添 良好 国际友人 思想道德 消费品 基础产业 两手抓 香港特别行政区 一国两制 综合国力 增多 科技成果 集中力量 邓小平理论 实力 解放思想 出现 过去 不变 初级阶段 进行 民族团结 有所提高 潰璨 多亿元 師鍥 负鍥 弗鎵 治安状况 退税率 多亿美元 物价上涨 产量 宏观经济 重点项目 有所改善 新开工 邓小平 多元 关税 外贸 进出口 职业 出口权 减债 开发技术 勤政廉政 承诺制 供应 适用技术 健身运动 购销两旺 今后 幅度 工交 重视 第八届全国人民代表大会 稳中求进 铺通 以丰补歉 体育健儿 半停产 八五 七五 远景 1996 簡姣 繃娣 害鏈 撲富 传宸 編濂界 夸富 婀鹃 婀句 汉绫昏 成绩显著 格局 生产力 零售物价 轻纺产品 进步 每周五 提前 大会 中共十四大 铺轨 万项 国际风云 簡鏈 患瑙備 垮乏 鍥扮 邯鏈 編濂 变腑 癸細 纰嶇 鐮存 村害 鍥界伯 翠慨 備埂 保持稳定 增加值 浣嶇 扣除 并轨 亿公斤 扩大开放 交换机 百分之十 程度 抓住机遇 因素 亿平方米 比较严重 综合治理 有所 以及 货币 决定性 放松 商品价格 价格上涨 新建 原油 汇率 棉花 港口 十一点七 不同 调节 百分之十八 百分之二十点 农业投入 乱涨价 缺乏活力 百分之三点 肉禽蛋 百分之七点 百分之八 共同奋斗 流转税 设备陈旧 长江三峡工程 必要 引大 入秦 侨务 但同 氫负 充節 1994 斂姣 繚璇 細鏈 娴峰场 中共中央 百分之二十 基本方针 胜利 改革方案 全党 大局 计算机 国内外 百分之十三点 认真 一百周年 基本上 百分之四 外贸体制 百分之十点 群众体育 比较顺利 点二 播映 画淇 共骞翠繚 颁互 界户 告攢姣 鍘裤 俯楗遍 绫嶇 細璐 勾璧峰 韩鍔 悶娲 汉韬 缓瑙 辨部 伙紱鍋 娴锋郸 部娴峰 父骞块 冪兢 垮洶 鸿繕 嬪己 帶璐 勾璐 负绀句 中心 1993 年同 鍥村 灑绾 嬪凡 浠界 冲伐 局面 亿吨公里 接近 保证 亿吨 百分之四十 经营机制 治理整顿 党的基本 百分之五十 物质文明 周转量 来之不易 沿边 利用外资 十一届三中全会 顺利进行 四项 基本建设 第七届 蓬勃发展 农副产品 复杂 货运 全方位 沿江 作风 才能 进一步提高 阶段 比上 总产值 省会 旺盛 开创 鸿础 解放 自然灾害 1992 鍥借 场宸 负淇 婀炬 诲崗 树立 基本路线 总结经验 犯罪活动 长期 贯彻执行 根本利益 打击 第一年 优越性 有利于 丑恶 社会化 外商 原则 根本原因 决不能 根本 反映 是否 从根本上 借鉴 回顾 一切 大胆 路线 百分之七 百分之十七 依法惩治 结存 拚搏 顺乎民意 只有 百分之十四 鲁布革 计划体制 力戒 先进 缩小差距 十年规划 连年丰收 得失成败 吸收 运用 紧密团结 符合 应当 一方有难 一九九 節鐧 工业生产 眾涓 細绮剧 細鍥 交宸 夸節 二千 画鏈 勾鏈 鏈虹數 數褰便 鑾峰 总产量 里程 整个 七千 六百 加工工业 一万四千 上升 三千八百 一百二十七 回落 五十一 1991 一九九一年 交鎵 父寰 嶄袱 夸憨宸 充骇 惰偉 嗚繕 背闈 悶濂戒 鑷充 數璐 煙鎵 荤數 嬪害 惧紡 師鏈 疆璐 句節 欢娌 鐐圭數 師娌 扮數 颁负 攢鏈 画璐 害闈 悍鏈 強濡 辜淇 細绂 板法 夸骇 備骇 緝宸 張鎵 嶄互 紡淇 存睜 父娴 存壙 繕璐枫 借川 鍥翠 捐憲 状况 由于 当前 改进 市场调节 动乱 产品 暴乱 廉政建设 计划生育 自由化 反对 资产阶级 适当 五项原则 充分发挥 安定团结 希望 产业政策 中国政府 计划经济 现象 学习 结合 柬埔寨 知识分子 几年 为了 内政 九十年代 和平共处 并且 风波 联合声明 政治局面 违法违纪 案件 指令性 之间 方向 颠覆 纠正 公司 活动 自觉 有关 以来 閾惰 党政机关 压缩 曠撼 備换 瑰師 过大 储蓄 经济过热 信贷 方针政策 总需求 加剧 商品 紧俏商品 工业品 1989 父鎬 強涓 伴噸 崗璁 妇琛 夸袱 編鍥 疆娴 铺张浪费 紧日子 认识 可比价格 撤并 权威 艰巨性 外汇 总供给 税收 半年 不够 十三届 指导 一心一意 今明两年 三中全会 上交 抢购 建成投产 商品经济 实践 价格体系 鍥炬 所有制 过程 展开 利益 企事业 通过 劳务 开始 许多 总揽全局 可能 改变 需要 日益 物价管理 1988 婚暱 翠互 氫环 鍥句 嗚壇 按璐 鍛樺線 有益 经营责任制 调动 不合理 外商独资 鑷虫 经过 人民解放军 两件 贡献 1987 濡備 捶宸 变細 曠函 垮彈 苟鏈 鐐广 人代会 人民警察 不正之风 保卫祖国 超额完成 工作人员 总的来看 大事 差价 高等教育 坚信 法律 产品质量 力量 艰苦 工作者 很大 缺点 必将 交通运输 审议 颁布 开拓前进 地区差价 公民 围绕 消除 外贸逆差 宏观控制 建设祖国 奋发努力 钢铁长城 可喜成果 六五 一九八五年 一九八 期间 五五 板甫 第七个 工农业 1986 氬強 一九七八年 重工业 财政收入 建国以来 形势 比例 一九五三年 三亿 在世界上 合计 国外 一九八三年 稳定增长 六亿 五千 一千四百 俊璐枫 变富 滑宸 害绀句 氫簡 虹爺 典腑 鑷宠 父鍔 嬪钩 变化 一九八四年 三千 一百零三 合作经营 一五 预算外 村办 六十二 三十七 相比 新路子 票证 一亿 位次 一千五百 三十二 形式 轻工业 1985 国民收入 速度 基数 职工 工资总额 数为 诞鍔 偉绉 宠疮 奖金 一系列 城乡经济 八元 深远 超过 越来越 一个 每人 意义 搞活 这是 单位 第四季度 金融体制 做到 中高档 五元 向前 温饱 消费水平 消费基金 友好关系 随着 核定 活跃 不严 二十六年 构思 推向 入手 省长 现在 其中 产业结构 投产 忽视 协商 结果 急剧 精神污染 承包 设计 自主权 利改税 包干 责任制 可以 国营 建筑业 商业 税利 经济特区 供销社 批发 购销 承包单位 搞好 大锅饭 按照 科研单位 着重 科研 规定 招标 职工队伍 工期 多种形式 科学技术 1984 以税代利 国营商业 父瑙 对于 投标 推行 内部 厂长 允许 适应 素质 对外贸易 科技人员 分配关系 制订 建筑 设备 实践证明 学校 利润 第二步 不论 打破 贸易中心 交流 商品交换 岗位津贴 工贸结合 技贸 知识 创造性 一九八二年 百分之三十 长期存在 一九七九年 一点 1983 紡娲 讳富 簡淇 四倍 拨乱反正 决定 住宅 四年 五万 指导思想 评为 亿万人民 噸宸 互杈 互瓒 婁负 婁汉 充互 競宸 鑲叉椿鍔 颁袱 积累率 四千人 二倍 千张 六倍 错划 百分之八十 在校生 心情舒畅 集体所有制 轨道 在校学生 造成 客观条件 劳动模范 指导方针 七百 十五万 热情 种种 副食品 第六个 递增 逛節 節鐐 要求 1982 數绔 九百 百分之十二 二十八年 一九八一年 三千六百 鲍瑗 娴枫 夸互 汉宸 戒細 环鎬绘 鑷达 勾鎵 樺療 氮璐圭 轰环 百分之六十 百分之五 根本好转 翻两番 本世纪末 六千 争取 前提 第五个 稳步发展 产值 二十年 关于 这个 一九八七年 百分之二十二点 三年计划 应该 利用 能够 首先 起来 现有 石油 相当 不能 现有企业 财政收支 这方面 而且 有步骤 充分 犯罪分子 加以 这种 毛泽东思想 引进 防止 机械 预计 联合 上半年 去年同期 节约 一部分 明年 标准煤 节约能源 国家计划 效果 经济作物 社队 材料 提高质量 管理体制 原料 勘探 竞争 自销 工业锅炉 共生矿 购买力 综合利用 油料 试行 协作 调查 烧油 劳动保护 生活资料 大力开展 上缴利润 原材料 党和政府 缝纫机 不足 发展缓慢 生产资料 自行车 品种 联合体 四人帮 林彪 霸权主义 四个 团结 发扬 权利 破坏 轻纺 阶级斗争 纪律 官僚主义 目前 毛泽东 专政 法制 无政府主义 阶级 自己 越南 但是 伟大 这样 帝国主义 就是 分子 千分之 劳动 义务 歪风邪气 以后 仍然 民主集中制 无产阶级 没有 着重点 台湾 他们 任何 毛主席 革命 揭批 反革命 超级大国 批判 修正主义 统一战线 周总理 指示 少数民族 苏联 粉碎 非洲 马克思主义 运动 反霸 干扰 侵略 阴谋 高速度 各条战线 一九七六年 大革命 篡党夺权 两霸 资本主义 四届 召开 基地 两国人民 大寨 苏美 文化大革命 人大 妄图 敌人 社员 两国关系 彻底 理论 认真执行 文艺 谬论 劳动竞赛 科学实验 教导 自治区 战争 不要 成为 正义斗争 八年 讨论 批林批孔 被压迫 一九七五年 上层建筑 争议地区 1975 团结起来 设想 边界 武装冲突 群众运动 争夺 第三世界 一九七四年 十年 永远 斗批改 本世纪内 一九六四年 加强团结 互不侵犯 宏伟目标 独立 列宁主义 伟大胜利 路线斗争 两个 全世界 国际主义 美苏 发动群众 激烈 新生事物 三届 全心全意 中苏 称霸 依靠 三倍 贫下中农 继续执行 殖民主义 工业体系 第四个 广大群众 战备 二十多年 共同努力 第四届 双方 互不 委员会 三点 两步 不论是 武装力量 封锁 第一步 工人阶级 民兵 武力 第三个 经济危机 缓和 争论 往来 解放以来 百分之八十五 学大庆 洋奴哲学 光荣任务 发扬成绩 克服缺点 脱离 那么 美帝国主义 总路线 反动派 自力更生 革命化 马克思列宁主义 指出 美国 错误 一九六五年 走狗 复辟 革命斗争 周恩来 高举 阵营 反帝 反华 核武器 支援 一九五七年 友好 保卫 新高潮 及其 民主革命 国际威望 拉丁美洲 强大 领土 巨大成就 相结合 下中农 劳动化 一九五九年 半农半读 文化战线 亚非 一次 封建主义 民主党派 参加 半工半读 发动 放手 强调指出 武装 工农兵 一九五八年 鼓掌 热烈鼓掌 西藏 跃进 一九五二年 大跃进 同时并举 战线 人民公社 运输 土法生产 体力劳动 爱好和平 整风运动 第一个 各个 帝国主义者 自我改造 岸信 工人 亿斤 阿拉伯 反动分子 帮助 叛乱 日本 东南亚 劳动力 中间 长时间 手工业 掌声 西藏地方 绝对数 叛乱分子 巨大 威胁 共产主义 或者 掌握 食堂 机械化 社办 半机械化 八字宪法 公社 万亩 合作社 一九五六年 棉田 十二年 消灭 人民公社化 两年 养猪 农具 普遍 完全 四十斤 群众性 改良 大大 高级 六十斤 麻雀 危害 技术革新 五亿 各地 精耕细作 因地 分配制度 执行 高级社 耕地 灌溉面积 1960 除四害 一九六七年 公布 不仅 八十斤 过渡 举办 卫生事业 百分之七十 大办 托儿所 一百斤 皮棉 科学试验 纲领 还要 亿亩 面积 动员 赶上 化肥厂 农作物 多种经营 病疫 园田化 办得 病虫害 二百 兴办 除了 鼓足干劲 零四个 亩产量 一千 集体福利 一九六二年 合理密植 事情 因此 供给制 二亿 公私合营 偏差 私营 充腑 洪樁 句富 颁腑 工商业者 工商业 鍥惧 合作化 簡鍥 簡鐧 骇宸 滑灏辨 变为 劳动改造 个别 管制 内部矛盾 五大 检查 1957 墜宸 鍛界 充娇 滅櫨 宠繕 汉姣 戒娇 绝大多数 敌我矛盾 处理 商店 肃清 性质 私方 灾荒 不是 合作商店 十亿斤 私有制 股息 来说 有人 农户 汉璇达 重新做人 第一届 变娇 簡绀句 滑鏈 翠唤 簡宸 交瑙 轰細 嶄富 充簡 绉嶇兢 鍛樹 借繕 惰繕 国家决算 占本 决算 总数 建设费 国营企业 原定 年收入 文教 收支 本年 片面 准备 提前完成 国防费 立井 工业部 收到 货物 拨付 秋征 钢材 将要 节减 年内 以外 中所 万担 年本 包括 数额 中央预算 建筑安装 信贷资金 年度计划 债款 以内 招生 公方 储备 农林水利 国家银行 开支 可比 其他支出 奖励制度 农业贷款 1956 共占本 商品流转 零售总额 统购 工业化 过渡时期 勾姣 柊绉嶇 猴細 颁娇 总任务 氬師 个体 落后 手工业者 轰節 富瑕 濮嬪 滑鎵 究鏈 鍥剧 环楂 小农经济 统治 一九四九年 中华人民共和国 1955 存偿 负鐧 跺壇 樹负 父娑 樹細 宪法 编制 列宁 生产方式 时间 钢铁厂 解放前 一九五四年 一九五 国家机关 等于 集团 日内瓦 中央人民政府 卖国 条约 浪费 军事同盟 协议 印度支那 集体 因为 计划供应 朝鲜 防务 容许 人民代表大会 所谓 不少 交通运输业 人民共和国 选举 四点 破坏活动 华侨 不顾 蒋介石
from collections import defaultdict
data = defaultdict(dict)
years = [int(i[:4]) for i in reports]
for i in wordset:
for year in years:
data[i][year] = 0
for txt in reports:
year = int(txt[:4])
print(year)
top1000= jieba.analyse.extract_tags(txt, topK=1000, withWeight=True)
for ww in top1000:
word, weight = ww
if word in wordset:
data[word][year]+= weight
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999
1998
1997
1996
1995
1994
1993
1992
1991
1990
1989
1988
1987
1986
1985
1984
1983
1982
1981
1980
1979
1978
1975
1964
1959
1960
1957
1956
1955
1954
word_weight = []
for i in data:
word_weight.append([i, np.sum(list(data[i].values()))])
word_weight.sort(key= lambda x:x[1], reverse = True )
top50 = [i[0] for i in word_weight[:50]]
' '.join(top50)
'发展 建设 改革 经济 推进 加强 句細 社会 政府 加快 工作 提高 实施 完善 企业 促进 创新 增长 全面 坚持 推动 社会主义 支持 政策 人民 就业 制度 国家 投资 增加 基本 鍥界 农村 扩大 问题 实现 跺害 农业 继续 鍥介 中国 取得 服务 氫富 归潰 重点 保障 国际 教育 群众'
def plotEvolution(word, color, linestyle, marker):
cx = data[word]
plt.plot(list(cx.keys()), list(cx.values()), color = color,
linestyle=linestyle, marker=marker, label= word)
plt.legend(loc=2,fontsize=18)
plt.ylabel(u'词语重要性')
plt.figure(figsize=(16, 6),facecolor='white')
plotEvolution(u'民主', 'g', '-', '>')
plotEvolution(u'法制', 'b', '-', 's')
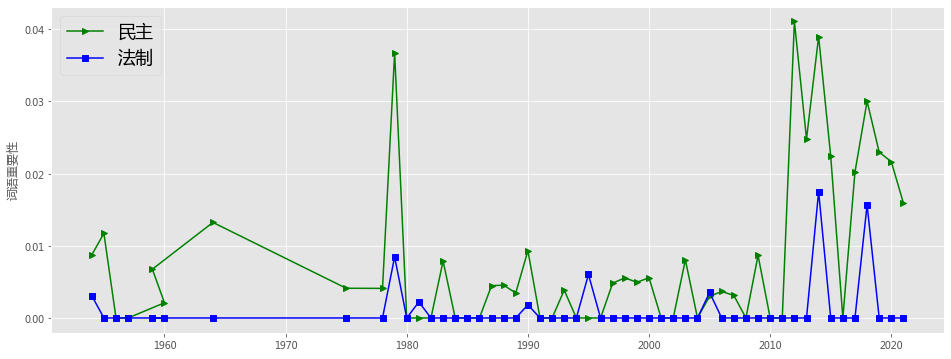
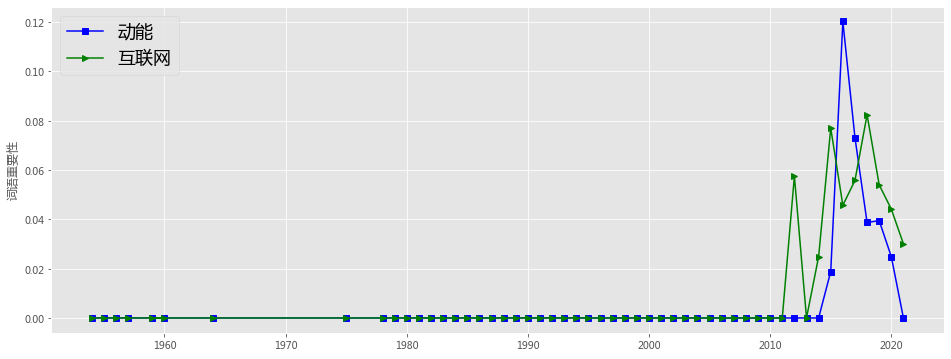
plt.figure(figsize=(16, 6),facecolor='white')
plotEvolution(u'动能', 'b', '-', 's')
plotEvolution(u'互联网', 'g', '-', '>')
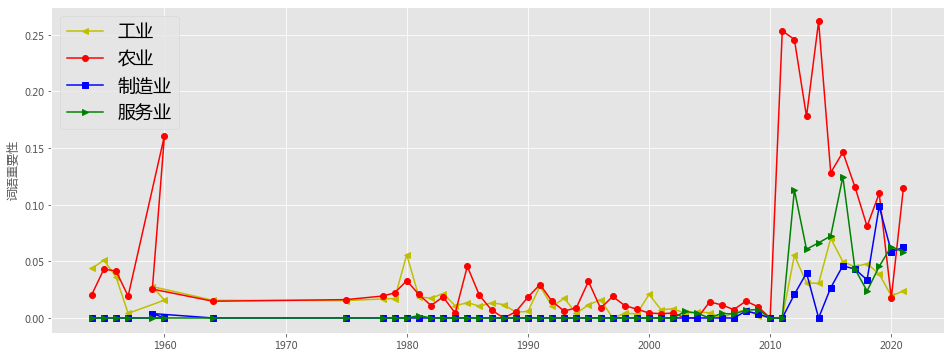
plt.figure(figsize=(16, 6),facecolor='white')
plotEvolution(u'工业', 'y', '-', '<')
plotEvolution(u'农业', 'r', '-', 'o')
plotEvolution(u'制造业', 'b', '-', 's')
plotEvolution(u'服务业', 'g', '-', '>')
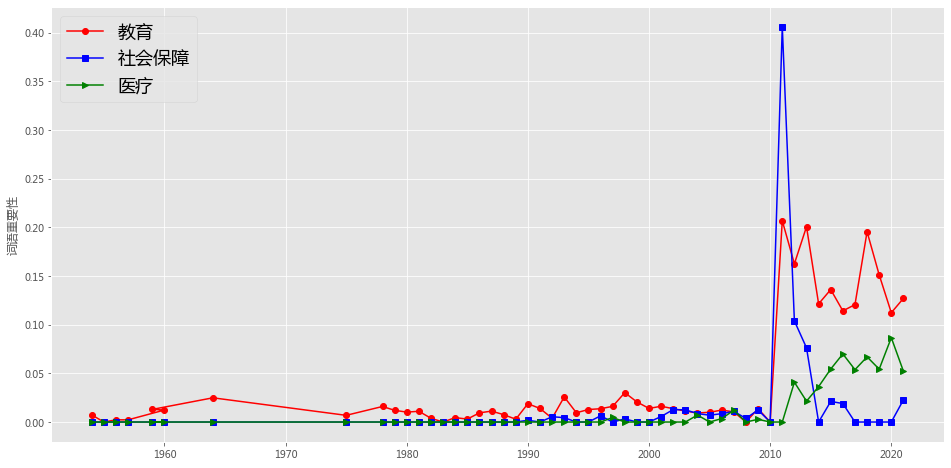
plt.figure(figsize=(16, 8),facecolor='white')
plotEvolution(u'教育', 'r', '-', 'o')
plotEvolution(u'社会保障', 'b', '-', 's')
plotEvolution(u'医疗', 'g', '-', '>')
plt.figure(figsize=(16, 8),facecolor='white')
plotEvolution(u'环境', 'b', '-', 's')
plotEvolution(u'住房', 'purple', '-', 'o')
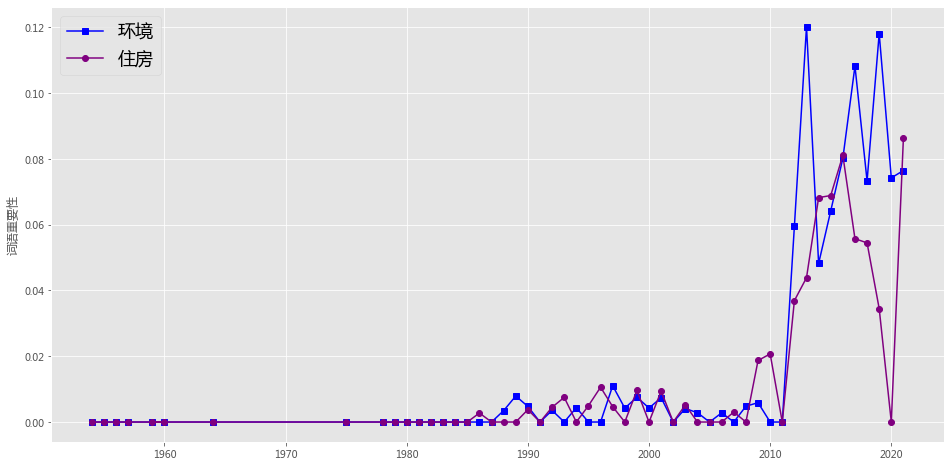
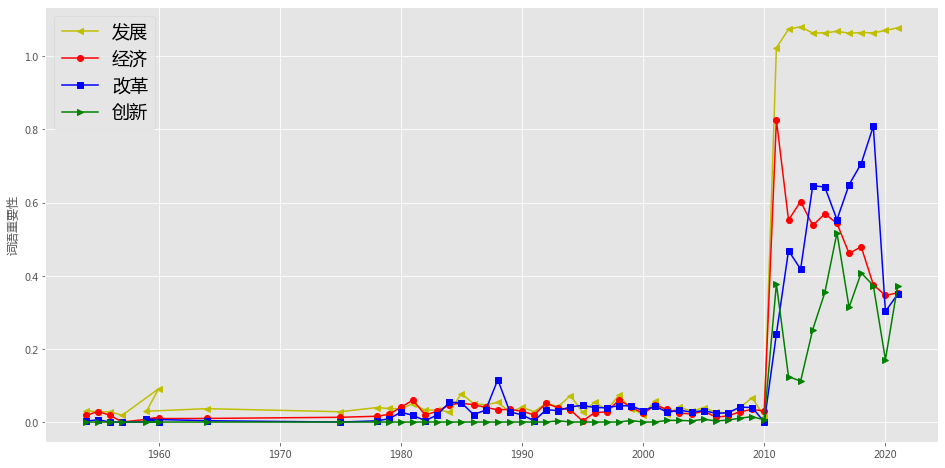
plt.figure(figsize=(16, 8),facecolor='white')
plotEvolution(u'发展', 'y', '-', '<')
plotEvolution(u'经济', 'r', '-', 'o')
plotEvolution(u'改革', 'b', '-', 's')
plotEvolution(u'创新', 'g', '-', '>')
plt.figure(figsize=(16, 6),facecolor='white')
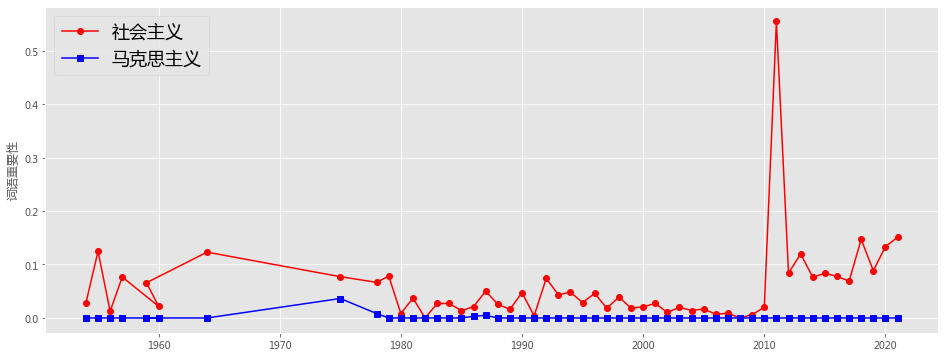
plotEvolution(u'社会主义', 'r', '-', 'o')
plotEvolution(u'马克思主义', 'b', '-', 's')