
LIWC: Linguistic Inquiry and Word Count analyzer#
Language left behind on social media exposes the emotional and cognitive costs of a romantic breakup
Sarah Seraj, Kate G. Blackburn, and James W. Pennebaker
PNAS February 16, 2021 118 (7) e2017154118; https://doi.org/10.1073/pnas.2017154118
Abstract
Using archived social media data, the language signatures of people going through breakups were mapped. Text analyses were conducted on 1,027,541 posts from 6,803 Reddit users who had posted about their breakups. The posts include users’ Reddit history in the 2 y surrounding their breakups across the various domains of their life, not just posts pertaining to their relationship. Language markers of an impending breakup were evident 3 mo before the event, peaking on the week of the breakup and returning to baseline 6 mo later. Signs included an increase in I-words, we-words, and cognitive processing words (characteristic of depression, collective focus, and the meaning-making process, respectively) and drops in analytic thinking (indicating more personal and informal language). The patterns held even when people were posting to groups unrelated to breakups and other relationship topics. People who posted about their breakup for longer time periods were less well-adjusted a year after their breakup compared to short-term posters. The language patterns seen for breakups replicated for users going through divorce (n = 5,144; 1,109,867 posts) or other types of upheavals (n = 51,357; 11,081,882 posts). The cognitive underpinnings of emotional upheavals are discussed using language as a lens.
日常生活中的情感分析
忧郁与自杀者往往在语言与文字之中发出可侦测的求救信号,但是我们能否有效的敏感到这些信息?(Chung & Pennebaker,2007)
初次约会对象之间几分钟的对话可以预测彼此的好感?情侣间的对话可以预测几个月之后持续交往的机率?(Ireland & Pennebaker,2010)
团体的凝聚力和合作倾向在对话之中就能够被侦测?(Gonzales,Hancock,& Pennebaker,2010)
日常生活中的情感分析
你的男/女朋友欺骗你吗?谎言侦测的研究,可以告诉你说谎的语言特性,让你分辨真假之间。(Newman,Pennebaker,Berry,& Richards,2003)
还用老套的占星术认识新朋友?最潮的语言分析可以助你一臂之力。(Pennebaker & King,1999)
岁月的印记不只在容颜,语言也可以揭开年龄的秘密。(Pennebaker & Stone,2003)
LIWC词库已经开发了不同的语言版本。英文 版LIWC目前包含了64个词语类别,例如,常用的语词类别(代名词、冠词、应和词、 停顿词等),以及心理特征类别词汇(情感词汇、认知词汇)等。该词典将情感词汇分为积极情感词汇和消极情感词汇。其中,消极情感词汇包括焦虑、愤怒和伤心。 https://liwc.wpengine.com/
The liwc Python Package#
# https://github.com/chbrown/liwc-python
pip install liwc
Requirement already satisfied: liwc in /opt/anaconda3/lib/python3.7/site-packages (0.5.0)
Note: you may need to restart the kernel to use updated packages.
import liwc
liwcPath = '/Users/datalab/OneDrive - nju.edu.cn/research/liwc/LIWC2007_English100131.dic'
parse, category_names = liwc.load_token_parser(liwcPath)
parse is a function from a token of text (a string) to a list of matching LIWC categories (a list of strings)
category_names is all LIWC categories in the lexicon (a list of strings)
https://www.liwc.net/LIWC2007LanguageManual.pdf
print(*parse('happy'))
affect posemo
print(*category_names)
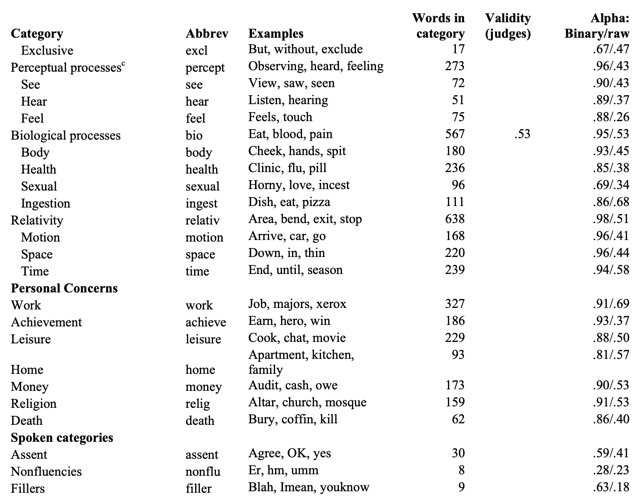
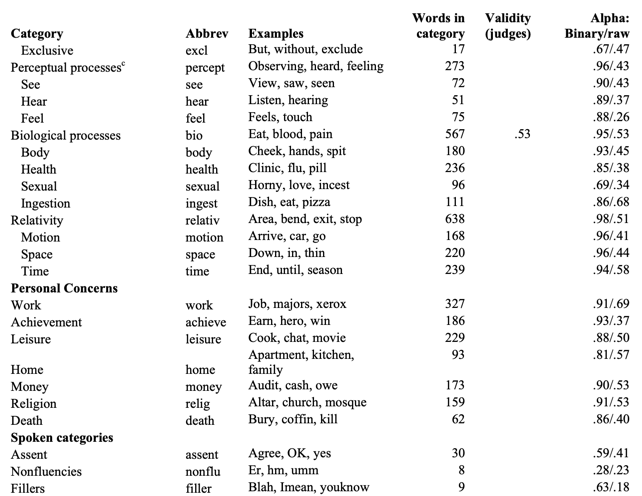
funct pronoun ppron i we you shehe they ipron article verb auxverb past present future adverb preps conj negate quant number swear social family friend humans affect posemo negemo anx anger sad cogmech insight cause discrep tentat certain inhib incl excl percept see hear feel bio body health sexual ingest relativ motion space time work achieve leisure home money relig death assent nonfl filler

The LIWC lexicon only matches lowercase strings, so you will most likely want to lowercase your input text before passing it to parse(…). In the example above, I call .lower() on the entire string, but you could alternatively incorporate that into your tokenization process (e.g., by using spaCy’s token.lower_).
import re
def tokenize(text):
# you may want to use a smarter tokenizer
for match in re.finditer(r'\w+', text, re.UNICODE):
yield match.group(0)
gettysburg = '''Four score and seven years ago our fathers brought forth on
this continent a new nation, conceived in liberty, and dedicated to the
proposition that all men are created equal. Now we are engaged in a great
civil war, testing whether that nation, or any nation so conceived and so
dedicated, can long endure. We are met on a great battlefield of that war.
We have come to dedicate a portion of that field, as a final resting place
for those who here gave their lives that that nation might live. It is
altogether fitting and proper that we should do this.'''.lower()
gettysburg_tokens = tokenize(gettysburg)
from collections import Counter
gettysburg_counts = Counter(category for token in gettysburg_tokens for category in parse(token))
print(gettysburg_counts)
Counter({'funct': 58, 'pronoun': 18, 'cogmech': 17, 'relativ': 17, 'verb': 13, 'ipron': 12, 'social': 11, 'preps': 10, 'conj': 9, 'incl': 9, 'space': 9, 'auxverb': 9, 'affect': 8, 'present': 8, 'time': 6, 'ppron': 6, 'article': 6, 'we': 5, 'posemo': 5, 'quant': 4, 'adverb': 4, 'past': 3, 'negemo': 3, 'anger': 3, 'tentat': 3, 'number': 2, 'motion': 2, 'certain': 2, 'death': 2, 'excl': 2, 'future': 2, 'family': 1, 'humans': 1, 'cause': 1, 'achieve': 1, 'work': 1, 'leisure': 1, 'they': 1, 'discrep': 1})
gettysburg_tokens = tokenize(gettysburg)
print(*gettysburg_tokens)
four score and seven years ago our fathers brought forth on this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equal now we are engaged in a great civil war testing whether that nation or any nation so conceived and so dedicated can long endure we are met on a great battlefield of that war we have come to dedicate a portion of that field as a final resting place for those who here gave their lives that that nation might live it is altogether fitting and proper that we should do this
# liwcPath = '/Users/datalab/bigdata/LIWC2007_100131.dic'
# parse, category_names = liwc.load_token_parser(liwcPath)
like (02 134)125/464 (02 134)126 253 466
Another Package with the same name
evanll/liwc-text-analysis-python
pip install liwc-text-analysis
from liwc import Liwc
liwc = Liwc(LIWC_FILEPATH)
Search a word in the dictionary to find in which LIWC categories it belongs
print(liwc.search('happy'))
[‘affect’, ‘posemo’]
Extract raw counts of words in a document that fall into the various LIWC categories
print(liwc.parse('I love ice cream.'.split(' ')))
Counter({‘verb’: 1, ‘present’: 1, ‘affect’: 1, ‘posemo’: 1, ‘bio’: 1, ‘sexual’: 1, ‘social’: 1})
CLIWC#
中文版的LIWC詞典(簡稱C-LIWC)也在Pennebaker教授的授權下,於2012建立並正式發表(黃金蘭等人2012) https://cliwc.weebly.com/
文心#
“文心(TextMind)”中文心理分析系统是由中科院心理所计算网络心理实验室研发的,针对中文文本进行语言分析的软件系统,通过“文心”,您可以便捷地分析文本中使用的不同类别语言的程度、偏好等特点。针对中国大陆地区简体环境下的语言特点,参照LIWC2007和正體中文C-LIWC词库,我们开发了“文心(TextMind)”中文心理分析系统。“文心”为用户提供从简体中文自动分词,到语言心理分析的一揽子分析解决方案,其词库、文字和符号等处理方法专门针对简体中文语境,词库分类体系也与LIWC兼容一致。 http://ccpl.psych.ac.cn/textmind/
liwc-analysis: Driver for LIWC2015 analysis.#
https://pypi.org/project/liwc-analysis/
pip install liwc-analysis
Collecting liwc-analysis
Downloading liwc_analysis-1.2.4-py2.py3-none-any.whl (5.5 kB)
Requirement already satisfied: pandas in /opt/anaconda3/lib/python3.7/site-packages (from liwc-analysis) (1.2.0)
Requirement already satisfied: pytz>=2017.3 in /opt/anaconda3/lib/python3.7/site-packages (from pandas->liwc-analysis) (2019.3)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/anaconda3/lib/python3.7/site-packages (from pandas->liwc-analysis) (2.8.1)
Requirement already satisfied: numpy>=1.16.5 in /opt/anaconda3/lib/python3.7/site-packages (from pandas->liwc-analysis) (1.18.1)
Requirement already satisfied: six>=1.5 in /opt/anaconda3/lib/python3.7/site-packages (from python-dateutil>=2.7.3->pandas->liwc-analysis) (1.12.0)
Installing collected packages: liwc-analysis
Successfully installed liwc-analysis-1.2.4
Note: you may need to restart the kernel to use updated packages.
# load file and save contents to text variable
rows = []
LIWCLocation = '/Users/datalab/OneDrive - nju.edu.cn/research/liwc/LIWC2007_100131.dic'
with open(LIWCLocation) as fp:
for line in fp:
rows.append(line)
grid = [row.strip().replace('\ufeff', '').split("\t") for row in rows if len(row) > 1]
grid = [i for i in grid if len(i) > 1]
num2cat = {i:j for i,j in grid[:66]}
len(num2cat)
66
dat = []
for i in grid[66:]:
word, nums = i[0], i[1:]
for j in nums:
if j in num2cat:
dat.append((word,num2cat[j]))
# write to file
with open('/Users/datalab/OneDrive - nju.edu.cn/research/liwc/LIWC2007_all_word_category_pair.txt', 'w') as f:
for (word, category) in dat:
f.write("{} ,{}\n".format(word, category))
import liwcanalysis
LIWCLocation = '/Users/datalab/OneDrive - nju.edu.cn/research/liwc/Simplified_Chinese_LIWC2015_word_category_pair.txt'
LIWC = liwcanalysis.liwc(LIWCLocation)
result_dics, coutn_dics = LIWC.analyze("我 今天 很 伤心 。")
import liwcanalysis
LIWCLocation = '/Users/datalab/OneDrive - nju.edu.cn/research/liwc/LIWC2007_all_word_category_pair.txt'
LIWC = liwcanalysis.liwc(LIWCLocation)
result_dics2, coutn_dics2 = LIWC.analyze("我 今天 很 开心 。")
result_dics3, coutn_dics3 = LIWC.analyze("I am very happy .")
for i,j in coutn_dics[0].items():
if j:
print(i,j)
adverb (Adverbs) 1
focuspresent (Present Focus) 1
function (Function Words) 3
i (I) 1
ppron (Personal Pronouns) 1
pronoun (Pronouns) 1
relativ (Relativity) 1
tensem 1
time (Time) 1
for i,j in coutn_dics2[0].items():
if j:
print(i,j)
adverb 1
funct 3
i 1
ppron 1
pronoun 1
relativ 1
time 1
for i,j in coutn_dics3[0].items():
if j:
print(i,j)
adverb 1
affect 1
auxverb 1
funct 2
higharousal 2
posemo 2
present 1
verb 1
for i,j in result_dics[0].items():
if j:
print(i,j)
adverb (Adverbs) ['很']
focuspresent (Present Focus) ['今天']
function (Function Words) ['我', '今天', '很']
i (I) ['我']
ppron (Personal Pronouns) ['我']
pronoun (Pronouns) ['我']
relativ (Relativity) ['今天']
tensem ['今天']
time (Time) ['今天']
for i,j in result_dics2[0].items():
if j:
print(i,j)
adverb ['很']
funct ['我', '今天', '很']
i ['我']
ppron ['我']
pronoun ['我']
relativ ['今天']
time ['今天']
for i,j in result_dics3[0].items():
if j:
print(i,j)
adverb ['very']
affect ['happy']
auxverb ['am']
funct ['am', 'very']
higharousal ['happy', 'happy']
posemo ['happy', 'happy']
present ['am']
verb ['am']
Chinese LIWC Lexicon#
Auto LIWC
Xiangkai Zeng, Cheng Yang, Cunchao Tu, Zhiyuan Liu, Maosong Sun. Chinese LIWC Lexicon Expansion via Hierarchical Classification of Word Embeddings with Sememe Attention. The 32nd AAAI Conference on Artificial Intelligence (AAAI 2018).
with open('./data/sc_liwc.dic', 'r') as f:
lines = f.readlines()
# https://github.com/thunlp/Auto_CLIWC/blob/master/utils/load_data.py
def load_liwc(filename, encoding='utf-8'):
import io
liwc_file = io.open(filename, 'r', encoding=encoding)
lines = liwc_file.readlines()
type2name = dict()
word2type = dict()
type2word = dict()
lc = 0
for i, line in enumerate(lines): # read type
if '%' in line:
lc = i
break
tmp = line.strip().split()
type2name[int(tmp[0])] = tmp[1]
for line in lines[lc + 1:]:
tmp = line.strip().split()
#if tmp[0] not in word2vec:
#continue
word2type[tmp[0]] = list(map(int, tmp[1:]))
for t in word2type[tmp[0]]:
type2word[t] = type2word.get(t, [])
type2word[t].append(tmp[0])
return type2name, word2type, type2word
type2name, word2type, type2word = load_liwc('./data/sc_liwc.dic')
len(type2name)
51
result_dics
[{'achieve (Achievement)': [],
'adverb (Adverbs)': ['很'],
'affect (Affect)': [],
'affiliation (Affiliation)': [],
'anger (Anger)': [],
'anx (Anx)': [],
'assent (Assent)': [],
'auxverb (Auxiliary Verbs)': [],
'bio (Biological Processes)': [],
'body (Body)': [],
'cause (Causal)': [],
'certain (Certainty)': [],
'cogproc (Cognitive Processes)': [],
'compare (Comparisons)': [],
'conj (Conjunctions)': [],
'death (Death)': [],
'differ (Differentiation)': [],
'discrep (Discrepancies)': [],
'drives (Drives)': [],
'family (Family)': [],
'feel (Feel)': [],
'female (Female)': [],
'filler (Filler Words)': [],
'focusfuture (Future Focus)': [],
'focuspast (Past Focus)': [],
'focuspresent (Present Focus)': ['今天'],
'friend (Friends)': [],
'function (Function Words)': ['我', '今天', '很'],
'general_pa': [],
'health (Health)': [],
'hear (Hear)': [],
'home (Home)': [],
'i (I)': ['我'],
'informal (Informal Language)': [],
'ingest (Ingest)': [],
'insight (Insight)': [],
'interrog (Interrogatives)': [],
'ipron (Impersonal Pronouns)': [],
'leisure (Leisure)': [],
'male (Male)': [],
'modal_pa': [],
'money (Money)': [],
'motion (Motion)': [],
'negate (Negations)': [],
'negemo (Negative Emotions)': [],
'netspeak (Netspeak)': [],
'nonflu (Nonfluencies)': [],
'number (Numbers)': [],
'particle': [],
'percept (Perceptual Processes)': [],
'posemo (Positive Emotions)': [],
'power (Power)': [],
'ppron (Personal Pronouns)': ['我'],
'prep (Prepositions)': [],
'prepend': [],
'progm': [],
'pronoun (Pronouns)': ['我'],
'quant (Quantifiers)': [],
'quanunit': [],
'relativ (Relativity)': ['今天'],
'relig (Religion)': [],
'reward (Reward)': [],
'risk (Risk)': [],
'sad (Sad)': [],
'see (See)': [],
'sexual (Sexual)': [],
'shehe (SheHe)': [],
'social (Social)': [],
'space (Space)': [],
'specart': [],
'swear (Swear)': [],
'tensem': ['今天'],
'tentat (Tentative)': [],
'they (They)': [],
'time (Time)': ['今天'],
'we (We)': [],
'work (Work)': [],
'you (You)': [],
'youpl': []}]
LIWC DIMENSION |
OUTPUT LABEL |
LIWC2015 MEAN |
LIWC2007 MEAN |
LIWC 2015/2007 CORRELATION |
||
Word Count |
WC |
11,921.82 |
11,852.99 |
1.00 |
||
Summary Variable |
||||||
Analytical Thinking |
Analytic |
56.34 |
||||
Clout |
Clout |
57.95 |
||||
Authentic |
Authentic |
49.17 |
||||
Emotional Tone |
Tone |
54.22 |
||||
Language Metrics |
||||||
Words per sentence1 |
WPS |
17.40 |
25.07 |
0.74 |
||
Words>6 letters |
Sixltr |
15.60 |
15.89 |
0.98 |
||
Dictionary words |
Dic |
85.18 |
83.95 |
0.94 |
||
Function Words |
function |
51.87 |
54.29 |
0.95 |
||
Total pronouns |
pronoun |
15.22 |
14.99 |
0.99 |
||
Personal pronouns |
ppron |
9.95 |
9.83 |
0.99 |
||
1st pers singular |
i |
4.99 |
4.97 |
1.00 |
||
1st pers plural |
we |
0.72 |
0.72 |
1.00 |
||
2nd person |
you |
1.70 |
1.61 |
0.98 |
||
3rd pers singular |
shehe |
1.88 |
1.87 |
1.00 |
||
3rd pers plural |
they |
0.66 |
0.66 |
0.99 |
||
Impersonal pronouns |
ipron |
5.26 |
5.17 |
0.99 |
||
Articles |
article |
6.51 |
6.53 |
0.99 |
||
Prepositions |
prep |
12.93 |
12.59 |
0.96 |
||
Auxiliary verbs |
auxverb |
8.53 |
8.82 |
0.96 |
||
Common adverbs |
adverb |
5.27 |
4.83 |
0.97 |
||
Conjunctions |
conj |
5.90 |
5.87 |
0.99 |
||
Negations |
negate |
1.66 |
1.72 |
0.96 |
||
Grammar Other |
||||||
Regular verbs |
verb |
16.44 |
15.26 |
0.72 |
||
Adjectives |
adj |
4.49 |
||||
Comparatives |
compare |
2.23 |
||||
Interrogatives |
interrog |
1.61 |
||||
Numbers |
number |
2.12 |
1.98 |
0.98 |
||
Quantifiers |
quant |
2.02 |
2.48 |
0.88 |
||
Affect Words |
affect |
5.57 |
5.63 |
0.96 |
||
Positive emotion |
posemo |
3.67 |
3.75 |
0.96 |
||
Negative emotion |
negemo |
1.84 |
1.83 |
0.96 |
||
Anxiety |
anx |
0.31 |
0.33 |
0.94 |
||
Anger |
anger |
0.54 |
0.60 |
0.97 |
||
Sadness |
sad |
0.41 |
0.39 |
0.92 |
||
Social Words |
social |
9.74 |
9.36 |
0.96 |
||
Family |
family |
0.44 |
0.38 |
0.94 |
||
Friends |
friend |
0.36 |
0.23 |
0.78 |
||
Female referents |
female |
0.98 |
||||
Male referents |
male |
1.65 |
||||
Cognitive Processes2 |
cogproc |
10.61 |
14.99 |
0.84 |
||
Insight |
insight |
2.16 |
2.13 |
0.98 |
||
Cause |
cause |
1.40 |
1.41 |
0.97 |
||
Discrepancies |
discrep |
1.44 |
1.45 |
0.99 |
||
Tentativeness |
tentat |
2.52 |
2.42 |
0.98 |
||
Certainty |
certain |
1.35 |
1.27 |
0.92 |
||
Differentiation3 |
differ |
2.99 |
2.48 |
0.85 |
||
Perpetual Processes |
percept |
2.70 |
2.36 |
0.92 |
||
Seeing |
see |
1.08 |
0.87 |
0.88 |
||
Hearing |
hear |
0.83 |
0.73 |
0.94 |
||
Feeling |
feel |
0.64 |
0.62 |
0.92 |
||
Biological Processes |
bio |
2.03 |
1.88 |
0.94 |
||
Body |
body |
0.69 |
0.68 |
0.96 |
||
Health/illness |
health |
0.59 |
0.53 |
0.87 |
||
Sexuality |
sexual |
0.13 |
0.28 |
0.76 |
||
Ingesting |
ingest |
0.57 |
0.46 |
0.94 |
||
Core Drives and Needs |
drives |
6.93 |
||||
Affiliation |
affiliation |
2.05 |
||||
Achievement |
achieve |
1.30 |
1.56 |
0.93 |
||
Power |
power |
2.35 |
||||
Reward focus |
reward |
1.46 |
||||
Risk/prevention focus |
risk |
0.47 |
||||
Time Orientation4 |
||||||
Past focus |
focuspast |
4.64 |
4.14 |
0.97 |
||
Present focus |
focuspresent |
9.96 |
8.10 |
0.92 |
||
Future focus |
focusfuture |
1.42 |
1.00 |
0.63 |
||
Relativity |
relativ |
14.26 |
13.87 |
0.98 |
||
Motion |
motion |
2.15 |
2.06 |
0.93 |
||
Space |
space |
6.89 |
6.17 |
0.96 |
||
Time |
time |
5.46 |
5.79 |
0.94 |
||
Personal Concerns |
||||||
Work |
work |
2.56 |
2.27 |
0.97 |
||
Leisure |
leisure |
1.35 |
1.37 |
0.95 |
||
Home |
home |
0.55 |
0.56 |
0.99 |
||
Money |
money |
0.68 |
0.70 |
0.97 |
||
Religion |
relig |
0.28 |
0.32 |
0.96 |
||
Death |
death |
0.16 |
0.16 |
0.96 |
||
Informal Speech |
informal |
2.52 |
||||
Swear words |
swear |
0.21 |
0.17 |
0.89 |
||
Netspeak |
netspeak |
0.97 |
||||
Assent |
assent |
0.95 |
1.11 |
0.68 |
||
Nonfluencies |
nonfl |
0.54 |
0.30 |
0.84 |
||
Fillers |
filler |
0.11 |
0.40 |
0.29 |
||
All Punctuation5 |
Allpunc |
20.47 |
22.90 |
0.96 |
||
Periods |
Period |
7.46 |
7.91 |
0.98 |
||
Commas |
Comma |
4.73 |
4.81 |
0.98 |
||
Colons |
Colon |
0.63 |
0.63 |
1.00 |
||
Semicolons |
SemiC |
0.30 |
0.24 |
0.98 |
||
Question marks |
QMark |
0.58 |
0.95 |
1.00 |
||
Exclamation marks |
Exclam |
1.0 |
0.91 |
1.00 |
||
Dashes |
Dash |
1.19 |
1.38 |
0.98 |
||
Quotation marks |
Quote |
1.19 |
1.38 |
0.76 |
||
Apostrophes |
Apostro |
2.13 |
2.83 |
0.76 |
||
Parentheses (pairs) |
Parenth |
0.52 |
0.25 |
0.90 |
||
Other punctuation |
OtherP |
0.72 |
1.38 |
0.98 |
References#
Pennebaker, J. W. (1997). Writing about emotional experiences as a therapeutic process. Psychological Science, 8, 162-166.
Pennebaker, J.W., & Francis, M.E. (1996). Cognitive, emotional, and language processes in disclosure. Cognition and Emotion, 10, 601-626.
Pennebaker, J.W., & King, L.A. (1999). Linguistic styles: Language use as an individual difference. Journal of Personality and Social Psychology, 77, 1296-1312.
Pennebaker, J. W., Mayne, T., & Francis, M. E. (1997). Linguistic predictors of adaptive bereavement. Journal of Personality and Social Psychology, 72, 863-871.
Pennebaker, J.W. (2002). What our words can say about us: Toward a broader language psychology. Psychological Science Agenda, 15, 8-9.
Newman, M.L., Pennebaker, J.W., Berry, D.S., & Richards, J.M. (2003). Lying words: Predicting deception from linguistic styles. Personality and social psychology bulletin, 29, 5, 665-675.