
VGG16预训练模型#
Author: Pytorch Team
Award winning ConvNets from 2014 Imagenet ILSVRC challenge
https://pytorch.org/hub/pytorch_vision_vgg/
https://pytorch.org/docs/stable/torchvision/models.html
Run it in colab#
https://colab.research.google.com/drive/1epVRmNLeoAenypwM1ffGeHv9pk1xtEek
This notebook is optionally accelerated with a GPU runtime.
If you would like to use this acceleration, please
select the menu option “Runtime” -> “Change runtime type”,
select “Hardware Accelerator” -> “GPU” and click “SAVE”
Load Pretrained Models#
import torch
model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg16', pretrained=True)
# or any of these variants
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg11_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg13', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg13_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg16', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg16_bn', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg19', pretrained=True)
# model = torch.hub.load('pytorch/vision:v0.6.0', 'vgg19_bn', pretrained=True)
model.eval()
Downloading: "https://github.com/pytorch/vision/archive/v0.6.0.zip" to /Users/datalab/.cache/torch/hub/v0.6.0.zip
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to /Users/datalab/.cache/torch/hub/checkpoints/vgg16-397923af.pth
Downloading: “pytorch/vision” to /root/.cache/torch/hub/v0.6.0.zip
Downloading: “https://download.pytorch.org/models/vgg16-397923af.pth” to /root/.cache/torch/hub/checkpoints/vgg16-397923af.pth
100% 528M/528M [00:02<00:00, 223MB/s]
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
All pre-trained models expect input images normalized in the same way,
i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224.
The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406]
and std = [0.229, 0.224, 0.225].
Here’s a sample execution.
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
{kind=link}
from PIL import Image
input_image = Image.open(filename)
input_image
# sample execution (requires torchvision)
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
input_prob = torch.nn.functional.softmax(output[0], dim=0)
torch.argmax(input_prob)
tensor(258, device='cuda:0')
# ImageNet挑战使用了一个“修剪”的1000个非重叠类的列表
import pandas as pd
url = 'https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json'
imagenet_df = pd.read_json(url).T
imagenet_df
| 0 | 1 | |
|---|---|---|
| 0 | n01440764 | tench |
| 1 | n01443537 | goldfish |
| 2 | n01484850 | great_white_shark |
| 3 | n01491361 | tiger_shark |
| 4 | n01494475 | hammerhead |
| ... | ... | ... |
| 995 | n13044778 | earthstar |
| 996 | n13052670 | hen-of-the-woods |
| 997 | n13054560 | bolete |
| 998 | n13133613 | ear |
| 999 | n15075141 | toilet_tissue |
1000 rows × 2 columns
imagenet_df.iloc[int(torch.argmax(input_prob))]
0 n02111889
1 Samoyed
Name: 258, dtype: object
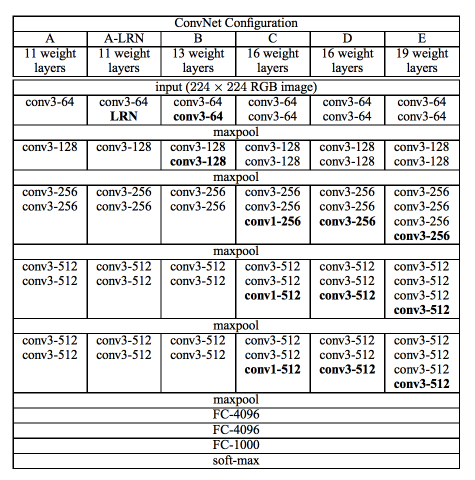
Model Description#
Here we have implementations for the models proposed in Very Deep Convolutional Networks for Large-Scale Image Recognition, for each configurations and their with bachnorm version.
For example, configuration A presented in the paper is vgg11, configuration B is vgg13, configuration D is vgg16
and configuration E is vgg19. Their batchnorm version are suffixed with _bn.
Their 1-crop error rates on imagenet dataset with pretrained models are listed below.
Model structure |
Top-1 error |
Top-5 error |
|---|---|---|
vgg11 |
30.98 |
11.37 |
vgg11_bn |
26.70 |
8.58 |
vgg13 |
30.07 |
10.75 |
vgg13_bn |
28.45 |
9.63 |
vgg16 |
28.41 |
9.62 |
vgg16_bn |
26.63 |
8.50 |
vgg19 |
27.62 |
9.12 |
vgg19_bn |
25.76 |
8.15 |
References