
抓取网易云音乐热门评论#
爬取网易云音乐的所有的歌曲的评论数。以下为主要思路:
爬取所有的歌手信息(artists.py);
根据上一步爬取到的歌手信息去爬取所有的专辑信息(album_by _artist.py);
根据专辑信息爬取所有的歌曲信息(music_by _album.py);
根据歌曲信息爬取其评论条数(comments_by _music.py)
爬取所有的歌手信息(artists.py)#
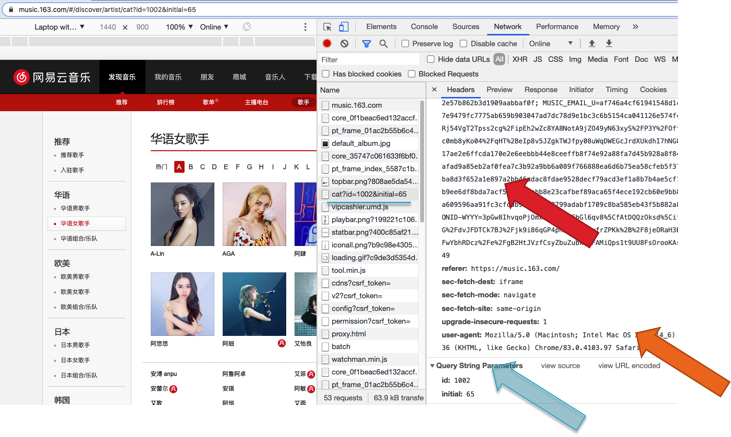
观察网易云音乐官网页面HTML结构
http://music.163.com/#/discover/artist/cat
http://music.163.com/#/discover/artist/cat?id=4003&initial=0
import requests
from bs4 import BeautifulSoup
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': '_ntes_nnid=7eced19b27ffae35dad3f8f2bf5885cd,1476521011210; _ntes_nuid=7eced19b27ffae35dad3f8f2bf5885cd; usertrack=c+5+hlgB7TgnsAmACnXtAg==; Province=025; City=025; NTES_PASSPORT=6n9ihXhbWKPi8yAqG.i2kETSCRa.ug06Txh8EMrrRsliVQXFV_orx5HffqhQjuGHkNQrLOIRLLotGohL9s10wcYSPiQfI2wiPacKlJ3nYAXgM; P_INFO=hourui93@163.com|1476523293|1|study|11&12|jis&1476511733&mail163#jis&320100#10#0#0|151889&0|g37_client_check&mailsettings&mail163&study&blog|hourui93@163.com; NTES_SESS=Fa2uk.YZsGoj59AgD6tRjTXGaJ8_1_4YvGfXUkS7C1NwtMe.tG1Vzr255TXM6yj2mKqTZzqFtoEKQrgewi9ZK60ylIqq5puaG6QIaNQ7EK5MTcRgHLOhqttDHfaI_vsBzB4bibfamzx1.fhlpqZh_FcnXUYQFw5F5KIBUmGJg7xdasvGf_EgfICWV; S_INFO=1476597594|1|0&80##|hourui93; NETEASE_AUTH_SOURCE=space; NETEASE_AUTH_USERNAME=hourui93; _ga=GA1.2.1405085820.1476521280; JSESSIONID-WYYY=cbd082d2ce2cffbcd5c085d8bf565a95aee3173ddbbb00bfa270950f93f1d8bb4cb55a56a4049fa8c828373f630c78f4a43d6c3d252c4c44f44b098a9434a7d8fc110670a6e1e9af992c78092936b1e19351435ecff76a181993780035547fa5241a5afb96e8c665182d0d5b911663281967d675ff2658015887a94b3ee1575fa1956a5a%3A1476607977016; _iuqxldmzr_=25; __utma=94650624.1038096298.1476521011.1476595468.1476606177.8; __utmb=94650624.20.10.1476606177; __utmc=94650624; __utmz=94650624.1476521011.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)',
'DNT': '1',
'Host': 'music.163.com',
'Pragma': 'no-cache',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
group_id = 1001
initial = 67
params = {'id': group_id, 'initial': initial}
r = requests.get('http://music.163.com/discover/artist/cat', params=params, headers=headers)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
hotartist_dic = {}
hot_artists = body.find_all('a', attrs={'class': 'msk'})
for artist in hot_artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
hotartist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
artist_dic = {}
artists = body.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'})
for artist in artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
artist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
artist_dic
{'2116': '陈奕迅',
'32897995': 'Copy',
'28083351': 'CORSAK胡梦周',
'34172520': 'C.HØPE',
'12157336': 'CMJ',
'28602303': '陈阳',
'1058228': '陈鸿宇',
'2112': '陈小春',
'2127': '陈柏宇',
'12932368': '蔡徐坤',
'963431': '陈致逸',
'12147170': '澄海伯伯',
'29234568': '陈亦洺',
'32720055': 'Crazy Donkey',
'30377220': '陈麒名',
'12519065': '程安',
'32973587': '陈大本事',
'34097618': 'ChenXi',
'1140028': '承利',
'2115': '陈百强',
'12193174': 'Capper',
'189955': '蔡翊昇',
'14420803': '陈雪燃',
'2110': '曹格',
'34918869': 'Cheng橙zzzz',
'12174110': '崔开潮',
'12276430': 'Cubi',
'12131566': 'CLOUDWANG 王云',
'2118': '成龙',
'2117': '侧田',
'14608268': 'Corki宗鑫',
'12095299': '陈柯宇',
'1084178': 'Candy_Wind',
'13447762': '陈亦云',
'13056440': '陈立农',
'13681463': '崔铭嘉',
'31005762': '冲矢昴',
'2331': '陈翔',
'31252052': '春野杉卉',
'33238413': '陈智凌',
'33320567': '苍弟(半吨兄弟)',
'34318343': 'Cc椿',
'2124': '陈楚生',
'12434106': '陈尤利',
'47136983': '陈恻',
'2201': '陈势安',
'34564181': '菜篮中的菜',
'1038074': '茶茶',
'33950188': 'CHENYI',
'31052925': '川屿',
'32440237': '蔡少铭',
'34318335': 'ChenYueLong.',
'46632613': '陈小潇',
'963409': '陈学冬',
'12536599': '迟柏林',
'12079044': '陈硕子',
'2153': '常石磊',
'2150': '陈冠蒲',
'32264375': '从和文',
'47060485': '晨晨没错了',
'30000267': '蔡耀轩',
'31087528': '陈奕辰Kane',
'4092': '春风哥',
'2130': '蔡国权',
'47383136': '陈宇鸣',
'12177051': 'C.A.R.L',
'1047298': 'CADY',
'2121': '蔡旻佑',
'2111': '崔健',
'2113': '车继铃',
'31665914': 'Cackle Joyful',
'29414807': '陈冬霖',
'12185665': 'C.vo',
'12291202': '陈曦',
'33394182': '陈志林Mega',
'33123519': '潮音锦式',
'34038223': '初梦',
'30437389': 'Chanlex',
'2294': '陈光荣',
'12490206': 'Credit',
'30117214': 'CrapBoy',
'12193309': 'CREAM D',
'33390699': '潮音铭帝',
'2338': '船长',
'33711050': 'CFrie木焱',
'34915098': '常泽浩',
'31093206': 'Cas14',
'27728315': '唇釉',
'1043290': '传琦SAMA',
'12459163': '陈嘉俊是这个嘉',
'2159': '曹轩宾',
'31055': 'Cee',
'36621645': 'CHANGAN',
'12700520': 'CJ 周密',
'2135': '陈勋奇',
'46507954': '川上島',
'31050529': '陈茗',
'2122': '陈冠希',
'2125': '陈晓东',
'12226597': '痴笑'}
def save_artist(group_id, initial, hot_artist_dic, artisti_dic):
params = {'id': group_id, 'initial': initial}
r = requests.get('http://music.163.com/discover/artist/cat', params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
hot_artists = body.find_all('a', attrs={'class': 'msk'})
artists = body.find_all('a', attrs={'class': 'nm nm-icn f-thide s-fc0'})
for artist in hot_artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
hot_artist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
for artist in artists:
artist_id = artist['href'].replace('/artist?id=', '').strip()
artist_name = artist['title'].replace('的音乐', '')
try:
artist_dic[artist_id] = artist_name
except Exception as e:
# 打印错误日志
print(e)
#return artist_dic, hot_artist_dic
gg = 1001
initial = 67
artist_dic = {}
hot_artist_dic = {}
save_artist(gg, initial, hot_artist_dic, artist_dic )
artist_dic
{'2116': '陈奕迅',
'32897995': 'Copy',
'28083351': 'CORSAK胡梦周',
'34172520': 'C.HØPE',
'12157336': 'CMJ',
'28602303': '陈阳',
'1058228': '陈鸿宇',
'2112': '陈小春',
'2127': '陈柏宇',
'12932368': '蔡徐坤',
'963431': '陈致逸',
'12147170': '澄海伯伯',
'29234568': '陈亦洺',
'32720055': 'Crazy Donkey',
'30377220': '陈麒名',
'12519065': '程安',
'32973587': '陈大本事',
'34097618': 'ChenXi',
'1140028': '承利',
'2115': '陈百强',
'12193174': 'Capper',
'189955': '蔡翊昇',
'14420803': '陈雪燃',
'2110': '曹格',
'34918869': 'Cheng橙zzzz',
'12174110': '崔开潮',
'12276430': 'Cubi',
'12131566': 'CLOUDWANG 王云',
'2118': '成龙',
'2117': '侧田',
'14608268': 'Corki宗鑫',
'12095299': '陈柯宇',
'1084178': 'Candy_Wind',
'13447762': '陈亦云',
'13056440': '陈立农',
'13681463': '崔铭嘉',
'31005762': '冲矢昴',
'2331': '陈翔',
'31252052': '春野杉卉',
'33238413': '陈智凌',
'33320567': '苍弟(半吨兄弟)',
'34318343': 'Cc椿',
'2124': '陈楚生',
'12434106': '陈尤利',
'47136983': '陈恻',
'2201': '陈势安',
'34564181': '菜篮中的菜',
'1038074': '茶茶',
'33950188': 'CHENYI',
'31052925': '川屿',
'32440237': '蔡少铭',
'34318335': 'ChenYueLong.',
'46632613': '陈小潇',
'963409': '陈学冬',
'12536599': '迟柏林',
'12079044': '陈硕子',
'2153': '常石磊',
'2150': '陈冠蒲',
'32264375': '从和文',
'47060485': '晨晨没错了',
'30000267': '蔡耀轩',
'31087528': '陈奕辰Kane',
'4092': '春风哥',
'2130': '蔡国权',
'47383136': '陈宇鸣',
'12177051': 'C.A.R.L',
'1047298': 'CADY',
'2121': '蔡旻佑',
'2111': '崔健',
'2113': '车继铃',
'31665914': 'Cackle Joyful',
'29414807': '陈冬霖',
'12185665': 'C.vo',
'12291202': '陈曦',
'33394182': '陈志林Mega',
'33123519': '潮音锦式',
'34038223': '初梦',
'30437389': 'Chanlex',
'2294': '陈光荣',
'12490206': 'Credit',
'30117214': 'CrapBoy',
'12193309': 'CREAM D',
'33390699': '潮音铭帝',
'2338': '船长',
'33711050': 'CFrie木焱',
'34915098': '常泽浩',
'31093206': 'Cas14',
'27728315': '唇釉',
'1043290': '传琦SAMA',
'12459163': '陈嘉俊是这个嘉',
'2159': '曹轩宾',
'31055': 'Cee',
'36621645': 'CHANGAN',
'12700520': 'CJ 周密',
'2135': '陈勋奇',
'46507954': '川上島',
'31050529': '陈茗',
'2122': '陈冠希',
'2125': '陈晓东',
'12226597': '痴笑'}
artist_dic = {}
hot_artist_dic = {}
for i in range(65, 91):
print(i)
save_artist(gg, i, hot_artist_dic, artist_dic )
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
len(hot_artist_dic)
260
len(artist_dic)
2600
爬取所有的专辑信息(album_by _artist.py)#
list(hot_artist_dic.keys())[0]
'12174057'
http://music.163.com/#/artist/album?id=89659&limit=400
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': '_ntes_nnid=7eced19b27ffae35dad3f8f2bf5885cd,1476521011210; _ntes_nuid=7eced19b27ffae35dad3f8f2bf5885cd; usertrack=c+5+hlgB7TgnsAmACnXtAg==; Province=025; City=025; _ga=GA1.2.1405085820.1476521280; NTES_PASSPORT=6n9ihXhbWKPi8yAqG.i2kETSCRa.ug06Txh8EMrrRsliVQXFV_orx5HffqhQjuGHkNQrLOIRLLotGohL9s10wcYSPiQfI2wiPacKlJ3nYAXgM; P_INFO=hourui93@163.com|1476523293|1|study|11&12|jis&1476511733&mail163#jis&320100#10#0#0|151889&0|g37_client_check&mailsettings&mail163&study&blog|hourui93@163.com; JSESSIONID-WYYY=189f31767098c3bd9d03d9b968c065daf43cbd4c1596732e4dcb471beafe2bf0605b85e969f92600064a977e0b64a24f0af7894ca898b696bd58ad5f39c8fce821ec2f81f826ea967215de4d10469e9bd672e75d25f116a9d309d360582a79620b250625859bc039161c78ab125a1e9bf5d291f6d4e4da30574ccd6bbab70b710e3f358f%3A1476594130342; _iuqxldmzr_=25; __utma=94650624.1038096298.1476521011.1476588849.1476592408.6; __utmb=94650624.11.10.1476592408; __utmc=94650624; __utmz=94650624.1476521011.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)',
'DNT': '1',
'Host': 'music.163.com',
'Pragma': 'no-cache',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
def save_albums(artist_id, albume_dic):
params = {'id': artist_id, 'limit': '200'}
# 获取歌手个人主页
r = requests.get('http://music.163.com/artist/album', headers=headers, params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
albums = body.find_all('a', attrs={'class': 'tit s-fc0'}) # 获取所有专辑
for album in albums:
albume_id = album['href'].replace('/album?id=', '')
albume_dic[albume_id] = artist_id
albume_dic = {}
save_albums('2116', albume_dic)
albume_dic
{'98517711': '2116',
'97079895': '2116',
'95509227': '2116',
'92392526': '2116',
'87540898': '2116',
'80538760': '2116',
'80235030': '2116',
'74268947': '2116',
'38296010': '2116',
'36304576': '2116',
'35835294': '2116',
'35643233': '2116',
'35520072': '2116',
'34961173': '2116',
'34923261': '2116',
'34881554': '2116',
'34735139': '2116',
'3404003': '2116',
'3319407': '2116',
'3279818': '2116',
'3184340': '2116',
'3279543': '2116',
'35406784': '2116',
'3109376': '2116',
'2801259': '2116',
'2793003': '2116',
'2786670': '2116',
'2767144': '2116',
'2732645': '2116',
'2518003': '2116',
'2532179': '2116',
'2499005': '2116',
'2465020': '2116',
'2302128': '2116',
'2261058': '2116',
'2261147': '2116',
'2261091': '2116',
'6335': '2116',
'6338': '2116',
'6339': '2116',
'6341': '2116',
'6343': '2116',
'2692242': '2116',
'2692238': '2116',
'6355': '2116',
'35663692': '2116',
'6360': '2116',
'6362': '2116',
'6365': '2116',
'6375': '2116',
'6378': '2116',
'35398900': '2116',
'6388': '2116',
'3211014': '2116',
'3102567': '2116',
'34611604': '2116',
'6394': '2116',
'3170625': '2116',
'2339617': '2116',
'6410': '2116',
'2692239': '2116',
'6404': '2116',
'3391071': '2116',
'6423': '2116',
'6429': '2116',
'6434': '2116',
'6437': '2116',
'6451': '2116',
'6452': '2116',
'6454': '2116',
'6462': '2116',
'6475': '2116',
'6479': '2116',
'6491': '2116',
'6483': '2116',
'6498': '2116',
'35411774': '2116',
'6510': '2116',
'6522': '2116',
'6530': '2116',
'3070638': '2116',
'6543': '2116',
'6548': '2116',
'6551': '2116',
'6555': '2116',
'6559': '2116',
'6562': '2116',
'6565': '2116',
'6567': '2116',
'6572': '2116',
'6581': '2116',
'2374009': '2116',
'6584': '2116',
'2374010': '2116',
'6590': '2116',
'2336647': '2116',
'6595': '2116',
'6599': '2116',
'2621232': '2116',
'2374011': '2116',
'6604': '2116',
'2374012': '2116',
'6607': '2116',
'6612': '2116',
'2374013': '2116',
'2374014': '2116',
'6620': '2116',
'6624': '2116',
'2332713': '2116'}
根据专辑信息爬取所有的歌曲信息(music_by _album.py)#
def save_music(album_id, music_dic):
params = {'id': album_id}
# 获取专辑对应的页面
r = requests.get('http://music.163.com/album', headers=headers, params=params)
# 网页解析
soup = BeautifulSoup(r.content.decode(), 'html.parser')
body = soup.body
musics = body.find('ul', attrs={'class': 'f-hide'}).find_all('li') # 获取专辑的所有音乐
for music in musics:
music = music.find('a')
music_id = music['href'].replace('/song?id=', '')
music_name = music.getText()
music_dic[music_id] = [music_name, album_id]
list(albume_dic.keys())[0]
'98517711'
music_dic = {}
save_music('6423', music_dic)
music_dic
{'65321': ['兄妹', '6423'],
'65326': ['十年', '6423'],
'65334': ['你的背包', '6423'],
'65337': ['K歌之王', '6423'],
'65342': ['Shall We Talk', '6423'],
'65347': ['低等动物', '6423'],
'65350': ['寂寞让你更快乐', '6423'],
'65355': ['圣诞结', '6423'],
'65360': ['想哭', '6423'],
'65365': ['不如这样', '6423'],
'65369': ['你会不会', '6423'],
'65373': ['Last Order', '6423'],
'65377': ['冤家', '6423'],
'65381': ['全世界失眠', '6423'],
'65385': ['我们都寂寞', '6423'],
'65389': ['阿怪', '6423'],
'65393': ['谢谢侬', '6423'],
'65397': ['爱是怀疑', '6423'],
'65400': ["Because You're Good To Me", '6423'],
'65403': ['Good Times', '6423'],
'65406': ['要你的', '6423'],
'65410': ['像一句广告', '6423'],
'65414': ['我也不会那样做', '6423'],
'65418': ['人造卫星', '6423'],
'65421': ['狂人日记', '6423'],
'65425': ['没有手机的日子', '6423'],
'65429': ['跳蚤市场', '6423'],
'65433': ['故事', '6423'],
'65437': ['男人的错', '6423'],
'65441': ['没有你', '6423']}
翻页的实现#
limit是一页的数量,offset往后的偏移。
比如limit是20,offset是40,就展示第三页的
http://music.163.com/api/v1/resource/comments/R_SO_4_516997458?limit=20&offset=0
http://music.163.com/api/v1/resource/comments/R_SO_4_516997458?limit=20&offset=20
http://music.163.com/api/v1/resource/comments/R_SO_4_516997458?limit=20&offset=40
另外一种方法#
from Crypto.Cipher import AES
import base64
import requests
import json
import time
# headers
headers = {
'Host': 'music.163.com',
'Connection': 'keep-alive',
'Content-Length': '484',
'Cache-Control': 'max-age=0',
'Origin': 'http://music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Accept': '*/*',
'DNT': '1',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4',
'Cookie': 'JSESSIONID-WYYY=b66d89ed74ae9e94ead89b16e475556e763dd34f95e6ca357d06830a210abc7b685e82318b9d1d5b52ac4f4b9a55024c7a34024fddaee852404ed410933db994dcc0e398f61e670bfeea81105cbe098294e39ac566e1d5aa7232df741870ba1fe96e5cede8372ca587275d35c1a5d1b23a11e274a4c249afba03e20fa2dafb7a16eebdf6%3A1476373826753; _iuqxldmzr_=25; _ntes_nnid=7fa73e96706f26f3ada99abba6c4a6b2,1476372027128; _ntes_nuid=7fa73e96706f26f3ada99abba6c4a6b2; __utma=94650624.748605760.1476372027.1476372027.1476372027.1; __utmb=94650624.4.10.1476372027; __utmc=94650624; __utmz=94650624.1476372027.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)',
}
#获取params
def get_params(first_param, forth_param):
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
h_encText = AES_encrypt(first_param, first_key.encode(), iv.encode())
h_encText = AES_encrypt(h_encText.decode(), second_key.encode(), iv.encode())
return h_encText.decode()
# 获取encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解AES秘
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text.encode())
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获取json数据
def get_json(url, data):
response = requests.post(url, headers=headers, data=data)
return response.content
# 传入post数据
def crypt_api(id, offset):
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_%s/?csrf_token=" % id
first_param = "{rid:\"\", offset:\"%s\", total:\"true\", limit:\"20\", csrf_token:\"\"}" % offset
forth_param = "0CoJUm6Qyw8W8jud"
params = get_params(first_param, forth_param)
encSecKey = get_encSecKey()
data = {
"params": params,
"encSecKey": encSecKey
}
return url, data
offset = 0
id = '516997458'
url, data = crypt_api(id, offset)
json_text = get_json(url, data)
json_dict = json.loads(json_text.decode("utf-8"))
comments_sum = json_dict['total']
comments_sum
8054
len(json_dict['comments'])
20
json_dict['comments'][0]
{'beReplied': [],
'commentId': 1112523641,
'content': '喜欢双笙,喜欢这首歌',
'isRemoveHotComment': False,
'liked': False,
'likedCount': 1,
'pendantData': None,
'time': 1525904882188,
'user': {'authStatus': 0,
'avatarUrl': 'http://p1.music.126.net/Eklu6D8QoR1Hb5UhLhCzPw==/109951163288324813.jpg',
'expertTags': None,
'experts': None,
'locationInfo': None,
'nickname': '狂妄嘻嘻',
'remarkName': None,
'userId': 1451756393,
'userType': 0,
'vipType': 0}}
json_dict['comments'][4]
{'beReplied': [{'content': '我们历史老师是一个年轻的小伙子。那是个阳光明媚的中午,他拖堂拖了很久,喇叭里响起了学校广播“校园之声”的开场白,接着就是这首歌。老师听到这首歌前奏后,自以为是地说一定是播音员自己唱的。我们都在下面反驳他,说人家歌就是这样的。。\n而现在,距中考只有58天了,毕业后,就回不去了。',
'status': 0,
'user': {'authStatus': 0,
'avatarUrl': 'http://p1.music.126.net/gm976KYbWTvYvExzjBNeaw==/109951163217371336.jpg',
'expertTags': None,
'experts': None,
'locationInfo': None,
'nickname': '惴洛',
'remarkName': None,
'userId': 1325932231,
'userType': 0,
'vipType': 0}}],
'commentId': 1112261542,
'content': '还有不到一个月了高一学姐祝你考试加油哦',
'isRemoveHotComment': False,
'liked': False,
'likedCount': 0,
'pendantData': None,
'time': 1525876023865,
'user': {'authStatus': 0,
'avatarUrl': 'http://p1.music.126.net/kAuCCkW-fcC7yu4wix9z5Q==/109951163144186242.jpg',
'expertTags': None,
'experts': None,
'locationInfo': None,
'nickname': '土园yy',
'remarkName': None,
'userId': 275653796,
'userType': 0,
'vipType': 0}}
offset = 20
id = '516997458'
url, data = crypt_api(id, offset)
json_text = get_json(url, data)
json_dict = json.loads(json_text.decode("utf-8"))
comments_sum = json_dict['total']
json_dict['comments'][0]
{'beReplied': [],
'commentId': 1107837178,
'content': '冥月声音好听好温柔[爱心]表白',
'isRemoveHotComment': False,
'liked': False,
'likedCount': 3,
'pendantData': None,
'time': 1525515089450,
'user': {'authStatus': 0,
'avatarUrl': 'http://p1.music.126.net/suhvzXk2pEUOaeHUPU0aQQ==/109951163173870029.jpg',
'expertTags': None,
'experts': None,
'locationInfo': None,
'nickname': '黴祇',
'remarkName': None,
'userId': 619018018,
'userType': 0,
'vipType': 0}}
offset = 40
id = '516997458'
url, data = crypt_api(id, offset)
json_text = get_json(url, data)
json_dict = json.loads(json_text.decode("utf-8"))
comments_sum = json_dict['total']
json_dict['comments'][0]
{'beReplied': [],
'commentId': 1102303635,
'content': '找这首歌找了好久了!!无厘头的找,今天无意居然听到了(*^▽^)/★*☆',
'isRemoveHotComment': False,
'liked': False,
'likedCount': 1,
'pendantData': None,
'time': 1525072647936,
'user': {'authStatus': 0,
'avatarUrl': 'http://p1.music.126.net/fU8tvMVN2f5WkSUZehQ21Q==/3274345636764863.jpg',
'expertTags': None,
'experts': None,
'locationInfo': None,
'nickname': '黎诺0',
'remarkName': None,
'userId': 129375977,
'userType': 0,
'vipType': 0}}
根据歌曲信息爬取其评论条数(comments_by _music.py#
http://music.163.com/#/song?id=516997458
很遗憾的是评论数虽然也在详情页内,但是网易云音乐做了防爬处理,
采用AJAX调用评论数API的方式填充评论相关数据,
异步的特性导致我们爬到的页面中评论数是空,
我们就找一找这个API吧,通关观察XHR请求发现是下面这个家伙..
响应结果很丰富呢,所有评论相关的数据都有,不过经过观察发现这个API是经过加密处理的,不过没关系…
https://blog.csdn.net/python233/article/details/72825003
https://www.zhihu.com/question/36081767
{'user': {'locationInfo': None, 'liveInfo': None, 'anonym': 0, 'userId': 130378562, 'avatarDetail': None, 'userType': 0, 'followed': False, 'mutual': False, 'remarkName': None, 'vipRights': None, 'nickname': '富士山下钟无艳-', 'avatarUrl': 'http://p2.music.126.net/AlUvuBnyf32Qs1bhtWQpvw==/109951163540816255.jpg', 'authStatus': 0, 'expertTags': None, 'experts': None, 'vipType': 0, 'commonIdentity': None}, 'beReplied': [], 'pendantData': None, 'showFloorComment': None, 'status': 0, 'commentId': 310484149, 'content': '这是那天她哭着唱的歌 因此这是我一辈子记得的歌@豆芽小张 ', 'time': 1487199594599, 'likedCount': 1811, 'expressionUrl': None, 'commentLocationType': 0, 'parentCommentId': 0, 'decoration': None, 'repliedMark': None, 'liked': False}