
使用Pyppeteer实现异步抓取!#
https://mp.weixin.qq.com/s/cWDbLcB_eYBDqBg11Jof3g
Selenium 库是一个自动化测试工具,很多人可能对它并不陌生,不过在使用 Selenium 过程中,会遇到一些麻烦的事情,如要提前准备好环境配置、驱动等,而且在大规模部署中也会与遇到让我们头疼的事情,那有什么解决方法呢?
Puppeteer 是 Google 基于 Node.js 开发的一个工具,有了它我们可以通过 JavaScript 来控制 Chrome 浏览器的一些操作,当然也可以用作网络爬虫上,其 API 极其完善,功能非常强大。
Pyppeteer 是 Puppeteer 的 Python 版本的实现。是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染
!pip3 install pyppeteer
Requirement already satisfied: pyppeteer in /opt/anaconda3/lib/python3.9/site-packages (0.2.6)
Requirement already satisfied: importlib-metadata>=1.4 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (4.8.1)
Requirement already satisfied: pyee<9.0.0,>=8.1.0 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (8.2.2)
Requirement already satisfied: websockets<10.0,>=9.1 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (9.1)
Requirement already satisfied: urllib3<2.0.0,>=1.25.8 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (1.26.7)
Requirement already satisfied: appdirs<2.0.0,>=1.4.3 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (1.4.4)
Requirement already satisfied: tqdm<5.0.0,>=4.42.1 in /opt/anaconda3/lib/python3.9/site-packages (from pyppeteer) (4.62.3)
Requirement already satisfied: zipp>=0.5 in /opt/anaconda3/lib/python3.9/site-packages (from importlib-metadata>=1.4->pyppeteer) (3.6.0)
import pyppeteer
!pip install pyquery
Collecting pyquery
Downloading pyquery-2.0.0-py3-none-any.whl (22 kB)
Collecting cssselect>=1.2.0
Downloading cssselect-1.2.0-py2.py3-none-any.whl (18 kB)
Requirement already satisfied: lxml>=2.1 in /opt/anaconda3/lib/python3.9/site-packages (from pyquery) (4.6.3)
Installing collected packages: cssselect, pyquery
Successfully installed cssselect-1.2.0 pyquery-2.0.0
import requests
from pyquery import PyQuery as pq
url = 'http://quotes.toscrape.com/js/'
response = requests.get(url)
doc = pq(response.text)
print('Quotes:', doc('.quote').length)
Quotes: 0
结果是 0,这就证明使用 requests 是无法正常抓取到相关数据的。因为什么?因为这个页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了 JavaScript 之后才呈现出来的,因此这些条目数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码。
分析网页源代码数据,如果数据是隐藏在 HTML 中的其他地方,以 JavaScript 变量的形式存在,直接提取就好了。
分析 Ajax,很多数据可能是经过 Ajax 请求时候获取的,所以可以分析其接口。
模拟 JavaScript 渲染过程,直接抓取渲染后的结果。
而 Pyppeteer 和 Selenium 就是用的第三种方法
import nest_asyncio
nest_asyncio.apply()
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://quotes.toscrape.com/js/')
doc = pq(await page.content())
print('Quotes:', doc('.quote').length)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Quotes: 10
Pyppeteer完成了浏览器的开启、新建页面、页面加载等操作。另外 Pyppeteer进行了异步操作,需要配合 async/await 关键词来实现。
首先, launch 方法会新建一个 Browser 对象,
然后赋值给 browser,
然后调用 newPage
方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象。
然后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载,加载完成之后再调用 content 方法,返回当前浏览器页面的源代码。
然后进一步地,用 pyquery 进行同样地解析,就可以得到 JavaScript 渲染的结果了。
另外其他的一些方法如调用 asyncio 的 get_event_loop 等方法的相关操作则属于 Python 异步 async 相关的内容了,大家如果不熟悉可以了解下 Python 的 async/await 的相关知识。
通过上面的代码,我们就可以完成 JavaScript 渲染页面的爬取了。
我们没有配置 Chrome 浏览器,
没有配置浏览器驱动,
免去了一些繁琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取!
# 模拟网页截图,保存 PDF
import asyncio
from pyppeteer import launch
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('http://quotes.toscrape.com/js/')
await page.screenshot(path='example.png')
await page.pdf(path='./data/example.pdf')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
# >>> {'width': 800, 'height': 600, 'deviceScaleFactor': 1}
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
{'width': 800, 'height': 600, 'deviceScaleFactor': 1}
详细用法#
了解了基本的实例之后,我们再来梳理一下 Pyppeteer 的一些基本和常用操作。
Pyppeteer 的几乎所有功能都能在其官方文档的 API Reference 里面找到https://miyakogi.github.io/pyppeteer/reference.html,
用到哪个方法就来这里查询就好了,参数不必死记硬背,即用即查就好。
开启浏览器#
使用 Pyppeteer 的第一步便是启动浏览器,首先我们看下怎样启动一个浏览器,其实就相当于我们点击桌面上的浏览器图标一样,把它开起来。用 Pyppeteer 完成同样的操作,只需要调用 launch 方法即可。
我们先看下 launch 方法的 API,链接为:
https://miyakogi.github.io/pyppeteer/reference.html#pyppeteer.launcher.launch
首先可以试用下最常用的参数 headless,
如果我们将它设置为 True 或者默认不设置它,在启动的时候我们是看不到任何界面的,
如果把它设置为 False,那么在启动的时候就可以看到界面了
一般我们在调试的时候会把它设置为 False,在生产环境上就可以设置为 True
import asyncio
from pyppeteer import launch
async def main():
await launch(headless=False)
await asyncio.sleep(10)
asyncio.get_event_loop().run_until_complete(main())
开启调试模式
比如在写爬虫的时候会经常需要分析网页结构还有网络请求,所以开启调试工具还是很有必要的,
我们可以将 devtools 参数设置为 True,
这样每开启一个界面就会弹出一个调试窗口,非常方便,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(devtools=True)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await asyncio.sleep(10)
asyncio.get_event_loop().run_until_complete(main())
args 参数禁用操作:
我们可以看到上面的一条提示:”Chrome 正受到自动测试软件的控制”,如何关闭呢?
browser = await launch(headless=False, args=['--disable-infobars'])
这里你只是把提示关闭了,有些网站还是会检测到是 webdriver 吧,比如淘宝检测到是 webdriver 就会禁止登录了,我们可以试试:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
爬虫的时候看到这界面是很让人崩溃的吧,而且这时候我们还发现了页面的 bug,整个浏览器窗口比显示的内容窗口要大,这个是某些页面会出现的情况,让人看起来很不爽。
我们可以先解决一下这个显示的 bug,需要设置下 window-size 还有 viewport,代码如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False,
args=[f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.taobao.com')
await asyncio.sleep(10)
asyncio.get_event_loop().run_until_complete(main())
OK,那刚才所说的 webdriver 检测问题怎样来解决呢?其实淘宝主要通过 window.navigator.webdriver 来对 webdriver 进行检测,所以我们只需要使用 JavaScript 将它设置为 false 即可,代码如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://login.taobao.com/member/login.jhtml?redirectURL=https://www.taobao.com/')
await page.evaluate(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
这里没加输入用户名密码的代码,当然后面可以自行添加,下面打开之后,我们点击输入用户名密码,然后这时候会出现一个滑动条,这里滑动的话,就可以通过了
OK,这样的话我们就成功规避了 webdriver 的检测,使用鼠标拖动模拟就可以完成淘宝的登录了。
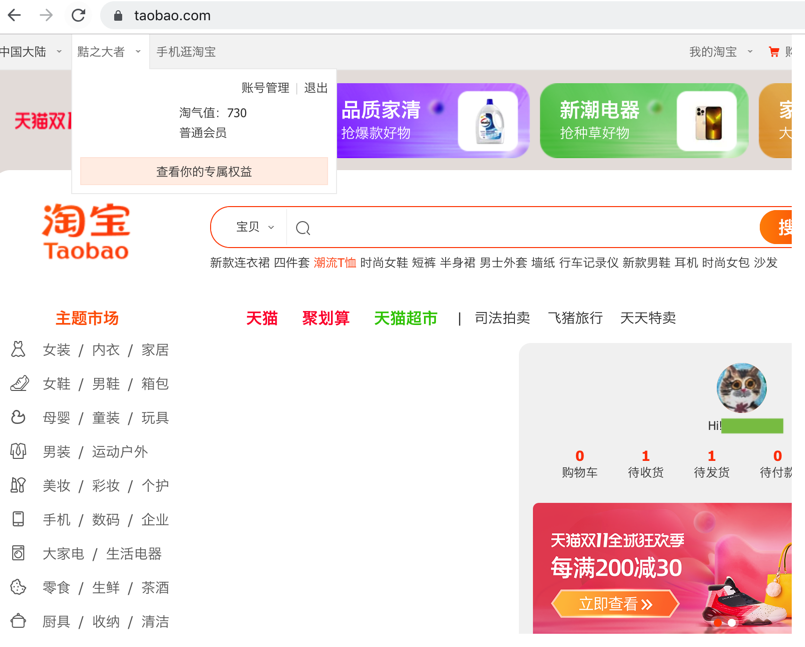
另一种方法设置用户目录
可以进一步免去淘宝登录的烦恼。平时我们已经注意到,当我们登录淘宝之后,如果下次再次打开浏览器发现还是登录的状态。这是因为淘宝的一些关键 Cookies 已经保存到本地了,下次登录的时候可以直接读取并保持登录状态。
这些信息保存在用户目录下了
里面不仅包含了浏览器的基本配置信息,
还有一些 Cache、Cookies 等各种信息都在里面
如果我们能在浏览器启动的时候读取这些信息,那么启动的时候就可以恢复一些历史记录甚至一些登录状态信息了。
这也就解决了一个问题:很多朋友在每次启动 Selenium 或 Pyppeteer 的时候总是是一个全新的浏览器,那就是没有设置用户目录,如果设置了它,每次打开就不再是一个全新的浏览器了,它可以恢复之前的历史记录,也可以恢复很多网站的登录信息。
那么这个怎么来做呢?很简单,在启动的时候设置 userDataDir 就好了,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='../userdata', args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://login.taobao.com/member/login.jhtml?redirectURL=https://www.taobao.com/')
await page.evaluate(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
上面👆代码加了一个 userDataDir 的属性,值为 userdata,即当前目录外面的 userdata 文件夹。
然后登录一次淘宝,这时候我们同时可以观察到在当前运行目录下又多了一个 userdata 的文件夹
下面👇代码再次运行,这时候可以发现现在就已经是登录状态了,不需要再次登录了,这样就成功跳过了登录的流程。
当然可能时间太久了,Cookies 都过期了,那还是需要登录的
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='../userdata', args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
具体的介绍可以看官方的一些说明,如:
https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md
这里面介绍了 userdatadir 的相关内容。
再次运行上面的代码,这时候可以发现现在就已经是登录状态了,不需要再次登录了,这样就成功跳过了登录的流程。当然可能时间太久了,Cookies 都过期了,那还是需要登录的。