Statistical Modeling with Python#
statsmodels is better suited for traditional stats
# the statsmodels.api uses numpy array notation
# statsmodels.formula.api use formula notation (similar to R's formula notation)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
A minimal OLS example#
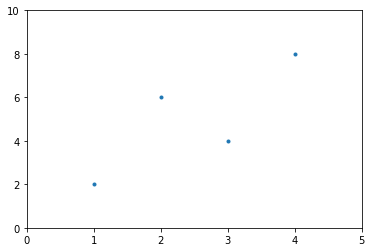
Four pairs of points
x = np.array([1,2,3,4])
y = np.array([2,6,4,8])
plt.scatter(x,y, marker = '.')
plt.xlim(0,5)
plt.ylim(0,10)
plt.show()
# make a dataframe of our data
d = pd.DataFrame({'x':x, 'y':y})
print(d)
x y
0 1 2
1 2 6
2 3 4
3 4 8
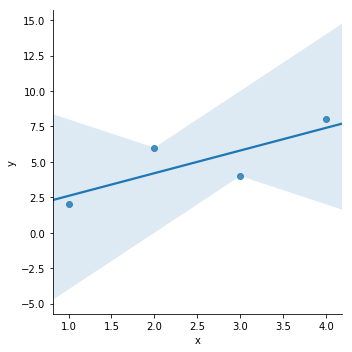
Seaborn lmplot
sns.lmplot(x = 'x', y = 'y', data = d)
<seaborn.axisgrid.FacetGrid at 0x17581f122e8>
Formula notation with statsmodels#
use statsmodels.formula.api (often imported as smf)
# data is in a dataframe
model = smf.ols('y ~ x', data = d)
# estimation of coefficients is not done until you call fit() on the model
results = model.fit()
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.640
Model: OLS Adj. R-squared: 0.460
Method: Least Squares F-statistic: 3.556
Date: Fri, 09 Nov 2018 Prob (F-statistic): 0.200
Time: 15:32:30 Log-Likelihood: -6.8513
No. Observations: 4 AIC: 17.70
Df Residuals: 2 BIC: 16.48
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.0000 2.324 0.430 0.709 -8.998 10.998
x 1.6000 0.849 1.886 0.200 -2.051 5.251
==============================================================================
Omnibus: nan Durbin-Watson: 3.400
Prob(Omnibus): nan Jarque-Bera (JB): 0.308
Skew: -0.000 Prob(JB): 0.857
Kurtosis: 1.640 Cond. No. 7.47
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
C:\Users\miles\Anaconda3\lib\site-packages\statsmodels\stats\stattools.py:72: ValueWarning: omni_normtest is not valid with less than 8 observations; 4 samples were given.
"samples were given." % int(n), ValueWarning)
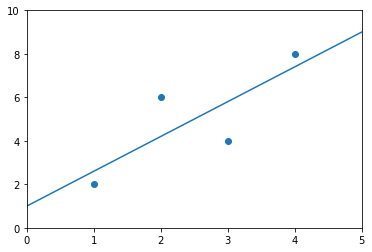
Using the abline_plot function for plotting the results
sm.graphics.abline_plot(model_results = results)
plt.scatter(d.x, d.y)
plt.xlim(0,5)
plt.ylim(0,10)
plt.show()
Generating an anova table
print(sm.stats.anova_lm(results))
df sum_sq mean_sq F PR(>F)
x 1.0 12.8 12.8 3.555556 0.2
Residual 2.0 7.2 3.6 NaN NaN
Making predictions
results.predict({'x' : 2})
0 4.2
dtype: float64
numpy array notation#
similar to sklearn’s notation
print(x)
[1 2 3 4]
X = sm.add_constant(x)
# need to add a constant for the intercept term.
# because we are using the numpy notation, we use sm rather than smf
print(X)
[[1. 1.]
[1. 2.]
[1. 3.]
[1. 4.]]
\[y_i = \beta_0 + \beta_1 x_i + \epsilon_i\]
\[\mathbf{\hat{Y}} = \boldsymbol{\beta} \mathbf{X}\]
# OLS is capitalized in the numpy notation
model2 = sm.OLS(y, X)
results2 = model2.fit()
print(results2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.640
Model: OLS Adj. R-squared: 0.460
Method: Least Squares F-statistic: 3.556
Date: Fri, 09 Nov 2018 Prob (F-statistic): 0.200
Time: 15:41:47 Log-Likelihood: -6.8513
No. Observations: 4 AIC: 17.70
Df Residuals: 2 BIC: 16.48
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.0000 2.324 0.430 0.709 -8.998 10.998
x1 1.6000 0.849 1.886 0.200 -2.051 5.251
==============================================================================
Omnibus: nan Durbin-Watson: 3.400
Prob(Omnibus): nan Jarque-Bera (JB): 0.308
Skew: -0.000 Prob(JB): 0.857
Kurtosis: 1.640 Cond. No. 7.47
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
C:\Users\miles\Anaconda3\lib\site-packages\statsmodels\stats\stattools.py:72: ValueWarning: omni_normtest is not valid with less than 8 observations; 4 samples were given.
"samples were given." % int(n), ValueWarning)
OLS solution#
\[(X^TX)^{-1}X^TY\]
X
array([[1., 1.],
[1., 2.],
[1., 3.],
[1., 4.]])
np.linalg.inv(X.T @ X) @ (X.T @ y)
array([1. , 1.6])
Plot Interaction of Categorical Factors#
https://www.statsmodels.org/dev/examples/notebooks/generated/categorical_interaction_plot.html
In this example, we will visualize the interaction between categorical factors. First, we will create some categorical data. Then, we will plot it using the interaction_plot function, which internally re-codes the x-factor categories to integers.
# https://stackoverflow.com/questions/55663474/interaction-plot-from-statsmodels-formula-api-using-python
import pandas as pd
from statsmodels.formula.api import ols
Consumption = [51, 52, 53, 54, 56, 57, 55, 56, 58, 59, 62, 63]
Gender = ["Male", "Male", "Male", "Male", "Male", "Male", "Female",
"Female", "Female", "Female", "Female", "Female"]
Income = [80, 80, 90, 90, 100, 100, 80, 80, 90, 90, 100, 100]
df = pd.DataFrame( {"Consumption": Consumption, "Gender": Gender, "Income": Income})
print(df)
Consumption Gender Income
0 51 Male 80
1 52 Male 80
2 53 Male 90
3 54 Male 90
4 56 Male 100
5 57 Male 100
6 55 Female 80
7 56 Female 80
8 58 Female 90
9 59 Female 90
10 62 Female 100
11 63 Female 100
Reg = ols(formula = "Consumption ~ Gender + Income + Gender*Income", data = df)
Fit = Reg.fit()
Fit.summary()
/opt/anaconda3/lib/python3.9/site-packages/scipy/stats/stats.py:1541: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=12
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
| Dep. Variable: | Consumption | R-squared: | 0.976 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.967 |
| Method: | Least Squares | F-statistic: | 108.4 |
| Date: | Thu, 13 Jan 2022 | Prob (F-statistic): | 8.11e-07 |
| Time: | 14:41:06 | Log-Likelihood: | -9.9135 |
| No. Observations: | 12 | AIC: | 27.83 |
| Df Residuals: | 8 | BIC: | 29.77 |
| Df Model: | 3 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 27.3333 | 3.059 | 8.935 | 0.000 | 20.279 | 34.387 |
| Gender[T.Male] | 4.0000 | 4.326 | 0.925 | 0.382 | -5.976 | 13.976 |
| Income | 0.3500 | 0.034 | 10.340 | 0.000 | 0.272 | 0.428 |
| Gender[T.Male]:Income | -0.1000 | 0.048 | -2.089 | 0.070 | -0.210 | 0.010 |
| Omnibus: | 2.522 | Durbin-Watson: | 3.273 |
|---|---|---|---|
| Prob(Omnibus): | 0.283 | Jarque-Bera (JB): | 0.970 |
| Skew: | -0.055 | Prob(JB): | 0.616 |
| Kurtosis: | 1.612 | Cond. No. | 2.62e+03 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 2.62e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
import matplotlib.pyplot as plt
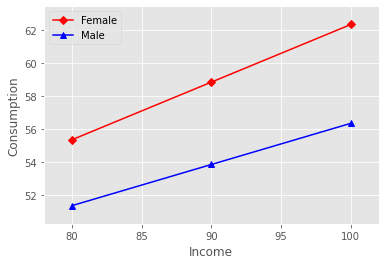
from statsmodels.graphics.factorplots import interaction_plot
plt.style.use('ggplot')
fig = interaction_plot(
x = Income,
trace = Gender,
response = Fit.fittedvalues,
colors = ['red','blue'],
markers = ['D','^'])
plt.xlabel('Income')
plt.ylabel('Consumption')
plt.legend().set_title(None)
plt.show()