In Depth: Naive Bayes Classification#

This notebook contains an excerpt from the Python Data Science Handbook by Jake VanderPlas; the content is available on GitHub.
The text is released under the CC-BY-NC-ND license, and code is released under the MIT license. If you find this content useful, please consider supporting the work by buying the book!
Naive Bayes models are a group of extremely fast and simple classification algorithms that are often suitable for very high-dimensional datasets.
A quick-and-dirty baseline for a classification problem.
so fast, so few tunable parameters, very useful
This section will focus on an intuitive explanation of how naive Bayes classifiers work
followed by a couple examples of them in action on some datasets.
Bayesian Classification#
We are intrested in finding the probability of a label given some observed features, \(P(L~|~{\rm features})\).
Bayes’s theorem: $\(P(L~|~{\rm features}) = \frac{P({\rm features}~|~L)P(L)}{P({\rm features})}=\frac{P({\rm features},~L)}{P({\rm features})}\)$
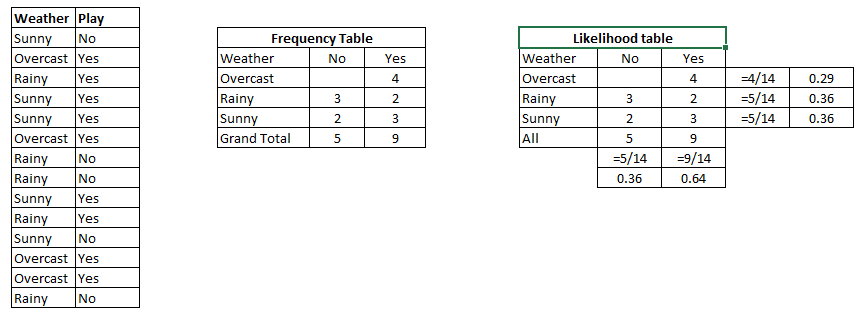
Step 1: Convert the data set into a frequency table
Step 2: Create Likelihood table by finding the probabilities like:
p(Overcast) = 0.29, p(rainy) = 0.36, p(sunny) = 0.36
p(playing) = 0.64, p(rest) = 0.36
Step 3: Now, use Naive Bayesian equation to calculate the posterior probability for each class. The class with the highest posterior probability is the outcome of prediction.
Problem: will the players play if weather is sunny?
We can solve it using above discussed method of posterior probability.
\(P(Yes | Sunny) = \frac{P( Sunny | Yes) * P(Yes) } {P (Sunny)}\)
Here we have P (Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P( Yes)= 9/14 = 0.64
Now, \(P (Yes | Sunny) = \frac{0.33 * 0.64}{0.36} = 0.60\), which has higher probability.
If we have \(d\) dummy/binary features, the size of sample space will be: \(2^d\)
It becomes almost impossible to estimate \(P(x | L)\) from the limited observational data.
估计类条件概率(Likelihood)的常用策略:先假定其具有某种确定的概率分布形式,再基于训练样本对概率分布参数估计。
Generative models (生成式模型):
先对联合概率分布\(P(L, x)\)建模, 再由此获得\(P(L|x)\)
Naive Bayes
Discrimitave models (判别式模型):
给定\(x\),直接建模\(P(L|x)\)来预测\(L\)
Decision Tree, SVM
If we are trying to decide between two labels \(L_1\) and \(L_2\)
to compute the ratio of the posterior probabilities for each label:
We need to compute \(P({\rm features}, L_i)\).
Such a model is called a generative model because it specifies the hypothetical random process that generates the data.
In practice, there is interest only in the numerator of that fraction,
because the denominator does not depend on \(L\) and the values of the features \(x_i\) are given
so that the denominator is effectively constant.
The numerator is equivalent to the joint probability model
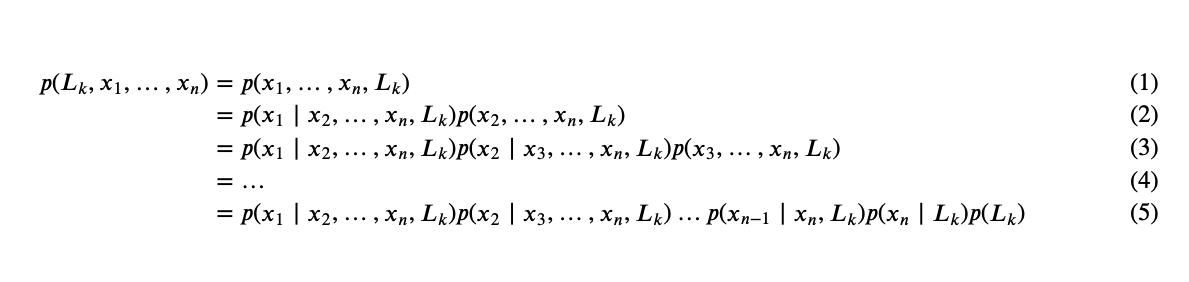
The “naive” conditional independent assumptions: assume that each feature \(x_i\) is conditionally statistical independence of every other feature \(x_j\) for \(j\neq i\), given the category \(L_k\). This means that
Thus, the joint model can be expressed as
The maximum a posteriori (MAP) decision rule
Specifying this generative model for each label is the main piece of the training of such a Bayesian classifier.
This is where the “naive” in “naive Bayes” comes in: if we make very naive assumptions about the generative model for each label,
we can find a rough approximation of the generative model for each class, and then proceed with the Bayesian classification.
Different types of naive Bayes classifiers rest on different naive assumptions about the data, and we will examine a few of these in the following sections.
Gaussian Naive Bayes#
Perhaps the easiest naive Bayes classifier to understand is Gaussian naive Bayes.
Previously, our data are discrete so we can use frequency to estimate probability
In this classifier, the assumption is that continuous data from each label is drawn from a simple Gaussian distribution.
A typical assumption is that the continuous values associated with each class are distributed according to a Normal distribution (Gaussian) distribution.
The probability density of the normal distribution is
Suppose the training data contains a continuous attribute, \(x\). We first segment the data by the class, and then compute the mean and variance of \(x\) in each class.
Let \(\mu_k\) be the mean of the values in \(x\) associated with class \(C_k\)
Let \(\sigma^2_k\) be the variance of the values in \(x\) associated with class \(C_k\).
Suppose we have collected some observation value \(v\). Then, the probability distribution of \(v\) given a class \(C_k\),
\(p(x=v \mid C_k)\), can be computed by plugging \(v\) into the equation for a Normal distribution parameterized by \(\mu_k\) and \(\sigma^2_k\). That is,
Problem: classify whether a given person is a male or a female based on the measured features.
Person |
height (feet) |
weight (lbs) |
foot size(inches) |
|---|---|---|---|
male |
6 |
180 |
12 |
male |
5.92 |
190 |
11 |
male |
5.58 |
170 |
12 |
male |
5.92 |
165 |
10 |
female |
5 |
100 |
6 |
female |
5.5 |
150 |
8 |
female |
5.42 |
130 |
7 |
female |
5.75 |
150 |
9 |
The classifier created from the training set using a Gaussian distribution assumption would be
Person |
mean (height) |
variance (height) |
mean (weight) |
variance (weight) |
mean (foot size) |
variance (foot size) |
|---|---|---|---|---|---|---|
male |
5.855 |
\( 3.5033 × 10^{−2}\) |
176.25 |
\(1.2292 × 10^2\) |
11.25 |
\(9.1667 × 10^{−1}\) |
female |
5.4175 |
\(9.7225 × 10^{−2}\) |
132.5 |
\(5.5833 × 10^2\) |
7.5 |
1.6667 |
Below is a sample to be classified as male or female.
Person |
height (feet) |
weight (lbs) |
foot size(inches) |
|---|---|---|---|
sample |
6 |
130 |
8 |
\(P(\text{male}) = 0.5\)
\(p({\text{height}} \mid \text{male}) = \frac{1}{\sqrt{2\pi \sigma^2}}\exp\left(\frac{-(6-\mu)^2}{2\sigma^2}\right) \approx 1.5789\),
where \(\mu = 5.855\) and \(\sigma^2 = 3.5033 \cdot 10^{-2}\)
Note that a value greater than 1 is OK here – it is a probability density rather than a probability, because ‘’height’’ is a continuous variable.
\(p({\text{weight}} \mid \text{male}) = \frac{1}{\sqrt{2\pi \sigma^2}}\exp\left(\frac{-(130-\mu)^2}{2\sigma^2}\right) = 5.9881 \cdot 10^{-6}\)
\(p({\text{foot size}} \mid \text{male}) = \frac{1}{\sqrt{2\pi \sigma^2}}\exp\left(\frac{-(8-\mu)^2}{2\sigma^2}\right) = 1.3112 \cdot 10^{-3}\)
\(\text{posterior numerator (male)} = \text{their product} = 6.1984 \cdot 10^{-9}\)
\(P({\text{female}}) = 0.5\)
\(p({\text{height}} \mid {\text{female}}) = 2.2346 \cdot 10^{-1}\)
\(p({\text{weight}} \mid {\text{female}}) = 1.6789 \cdot 10^{-2}\)
\(p({\text{foot size}} \mid {\text{female}}) = 2.8669 \cdot 10^{-1}\)
\(\text{posterior numerator (female)} = \text{their product} = 5.3778 \cdot 10^{-4}\)
Since posterior numerator is greater in the female case, we predict the sample is female.
https://en.wikipedia.org/wiki/Naive_Bayes_classifier
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sklearn.datasets import make_blobs
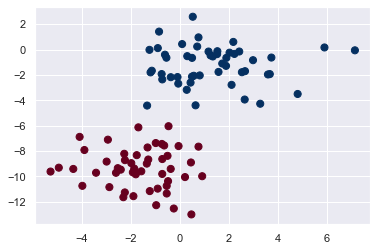
X, y = make_blobs(100, 2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu');
One extremely fast way to create a simple model is to assume that
the data is described by a Gaussian distribution with no covariance between dimensions.
This model can be fit by
simply finding the mean and standard deviation of the points within each label
The result of this naive Gaussian assumption is shown in the following figure:
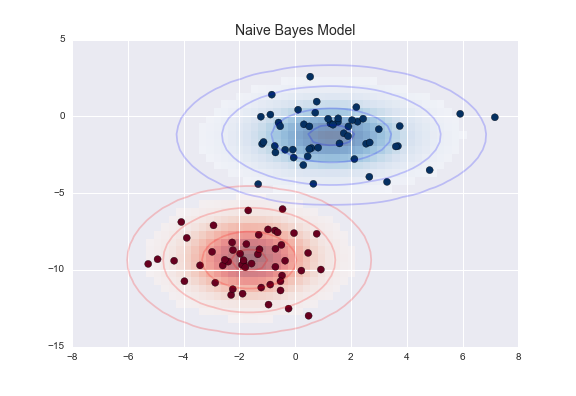 figure source in Appendix
figure source in Appendix
The ellipses here represent the Gaussian generative model for each label
with larger probability toward the center of the ellipses.
With this generative model in place for each class, we have a simple recipe to compute the likelihood \(P({\rm features}~|~L_1)\) for any data point
and thus we can quickly compute the posterior ratio and determine which label is the most probable for a given point.
This procedure is implemented in Scikit-Learn’s sklearn.naive_bayes.GaussianNB estimator:
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y);
Now let’s generate some new data and predict the label:
rng = np.random.RandomState(0)
Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2)
ynew = model.predict(Xnew)
Now we can plot this new data to get an idea of where the decision boundary is:
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='RdBu')
lim = plt.axis()
plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap='RdBu', alpha=0.1)
plt.axis(lim);
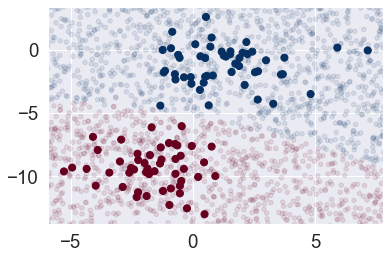
We see a slightly curved boundary in the classifications—in general, the boundary in Gaussian naive Bayes is quadratic.
A nice piece of this Bayesian formalism is that it naturally allows for probabilistic classification, which we can compute using the predict_proba method:
yprob = model.predict_proba(Xnew)
yprob[-8:].round(2)
# The columns give the posterior probabilities of the first and second label, respectively.
array([[0.89, 0.11],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.15, 0.85]])
If you are looking for estimates of uncertainty in your classification, Bayesian approaches like this can be a useful approach.
The final classification will only be as good as the model assumptions that lead to it
This is why Gaussian naive Bayes often does not produce very good results.
Multinomial Naive Bayes#
It assumes that the features are generated from a simple multinomial distribution.
The multinomial distribution describes the probability of observing counts among a number of categories,
It is most appropriate for features that represent counts or count rates.
The idea is precisely the same as before, but we model the data distribuiton with a best-fit multinomial distribution.
Example: Classifying Text#
One place where multinomial naive Bayes is often used is in text classification
the features are related to word counts or frequencies within the documents to be classified.
the extraction of such features from text in Feature Engineering.
Using the sparse word count features from the 20 Newsgroups corpus to classify these documents.
Let’s download the data and take a look at the target names:
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names
/opt/anaconda3/lib/python3.7/site-packages/sklearn/utils/deprecation.py:144: FutureWarning: The sklearn.datasets.base module is deprecated in version 0.22 and will be removed in version 0.24. The corresponding classes / functions should instead be imported from sklearn.datasets. Anything that cannot be imported from sklearn.datasets is now part of the private API.
warnings.warn(message, FutureWarning)
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
For simplicity here, we will select just a few of these categories, and download the training and testing set:
categories = ['talk.religion.misc', 'soc.religion.christian',
'sci.space', 'comp.graphics']
train = fetch_20newsgroups(subset='train', categories=categories)
test = fetch_20newsgroups(subset='test', categories=categories)
Here is a representative entry from the data:
print(train.data[5])
From: dmcgee@uluhe.soest.hawaii.edu (Don McGee)
Subject: Federal Hearing
Originator: dmcgee@uluhe
Organization: School of Ocean and Earth Science and Technology
Distribution: usa
Lines: 10
Fact or rumor....? Madalyn Murray O'Hare an atheist who eliminated the
use of the bible reading and prayer in public schools 15 years ago is now
going to appear before the FCC with a petition to stop the reading of the
Gospel on the airways of America. And she is also campaigning to remove
Christmas programs, songs, etc from the public schools. If it is true
then mail to Federal Communications Commission 1919 H Street Washington DC
20054 expressing your opposition to her request. Reference Petition number
2493.
To convert the content of each string into a vector of numbers.
Use TF-IDF vectorizer (discussed in Feature Engineering)
Create a pipeline that attaches it to a multinomial naive Bayes classifier:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
With this pipeline, we can apply the model to the training data, and predict labels for the test data:
model.fit(train.data, train.target)
labels = model.predict(test.data)
Evaluate the performance of the estimator.
the confusion matrix between the true and predicted labels for the test data
# confusion matrix
from sklearn.metrics import confusion_matrix
sns.set_context("notebook", font_scale=1.7)
mat = confusion_matrix(test.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=train.target_names, yticklabels=train.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');
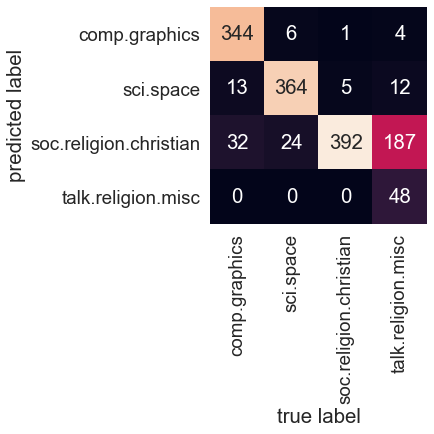
Evidently, even this very simple classifier can successfully separate space talk from computer talk,
but it gets confused between talk about religion and talk about Christianity.
This is perhaps an expected area of confusion!
The very cool thing here we now have the tools to determine the category for any string
using the
predict()method of this pipeline.
# Here's a quick utility function that will return the prediction for a single string:
def predict_category(s, train=train, model=model):
pred = model.predict([s])
return train.target_names[pred[0]]
Let’s try it out:
predict_category('sending a payload to the ISS')
'sci.space'
predict_category('discussing islam vs atheism')
'soc.religion.christian'
predict_category('determining the screen resolution')
'comp.graphics'
Remember that this is nothing more sophisticated than a simple probability model for the (weighted) frequency of each word in the string;
nevertheless, the result is striking.
Even a very naive algorithm, when used carefully and trained on a large set of high-dimensional data, can be surprisingly effective.
When to Use Naive Bayes#
Because naive Bayesian classifiers make such stringent assumptions about data, they will generally not perform as well as a more complicated model.
Advantages:
They are extremely fast for both training and prediction
They provide straightforward probabilistic prediction
They are often very easily interpretable
They have very few (if any) tunable parameters
A good choice as an initial baseline classification.
If it performs suitably, then congratulations: you have a very fast, very interpretable classifier for your problem.
When the naive assumptions actually match the data (very rare in practice)
For very well-separated categories, when model complexity is less important
For very high-dimensional data, when model complexity is less important
If it does not perform well, then you can begin exploring more sophisticated models, with some baseline knowledge of how well they should perform.
The last two points seem distinct, but they actually are related:
as the dimension of a dataset grows, it is much less likely for any two points to be found close together (after all, they must be close in every single dimension to be close overall).
clusters in high dimensions tend to be more separated, on average, than clusters in low dimensions, assuming the new dimensions actually add information.
simplistic classifiers like naive Bayes tend to work as well or better than more complicated classifiers as the dimensionality grows: once you have enough data, even a simple model can be very powerful.